An interesting use-case has come up with Drillbridge recently where drill-through is currently being “handled” with an Access database. I put the quotes around handled because the current solution requires the user to look at the current POV and then go fetch the corresponding data from an Access database. You might be thinking that this setup is horribly sub-optimal, but I wouldn’t characterize it as such. In my career on all sides of Hyperion – a developer, a consultant, and software developer – I have seen this pattern (particularly those involving Access) pop up again and again.
Access is often (perhaps all too often) the glue that binds finance solutions together, particularly in cases like this involving drill-through. It’s cheap, you can use it on the network simply by dropping the file onto a share drive, it gives you a quick and dirty GUI, and more. Many EPM projects I have been on involve many deliverables, often including drill-through. And all too often those projects had to cut it due to budget and time constraints. And if it gets cut, sure, finance might have to do the “quick and dirty” option like this with Access.
Now, the request du jour: use Drillbridge to quickly implement true drill-through, where the data currently resides in an Access database? A couple of options come to mind:
- JDBC to ODBC data bridge to access current Access database
- Export Access data to relational database
- Export to CSV and access via JDBC CSV reader
- Read CSV dynamically using Drillbridge’s embedded database
I won’t bore you with an exhaustive discussion of the pros and cons of these options, but I will say that the JDBC/ODBC bridge was a non-starter from the get-go (for me), mostly because I looked into it for another project years ago and the general consensus from Sun/Oracle was a) don’t do that [anymore] and b) performance is not too great. Regarding exporting Access to a relational database, yes that is more towards the ideal configuration, but if that were an easy/quick option in this case, we probably wouldn’t be on Access already (i.e., for whatever reason, finance didn’t have the time/patience to have the IT department stand up and manage a relational database, to say nothing of maintenance, ETL, and other things). Next, while there are a handful of JDBC CSV readers, they seem to have their quirks and various unsupported features, and hey, as it turns out, Drillbridge’s embedded database actually ships with a pretty capable CSV reading capability that let’s us essentially treat CSV files as tables, so that sounds perfect, and bonus: no additional JDBC drivers to ship. So let’s focus on that option and how to set it up!
Getting Started
Access Drillbridge and configure a new connection:
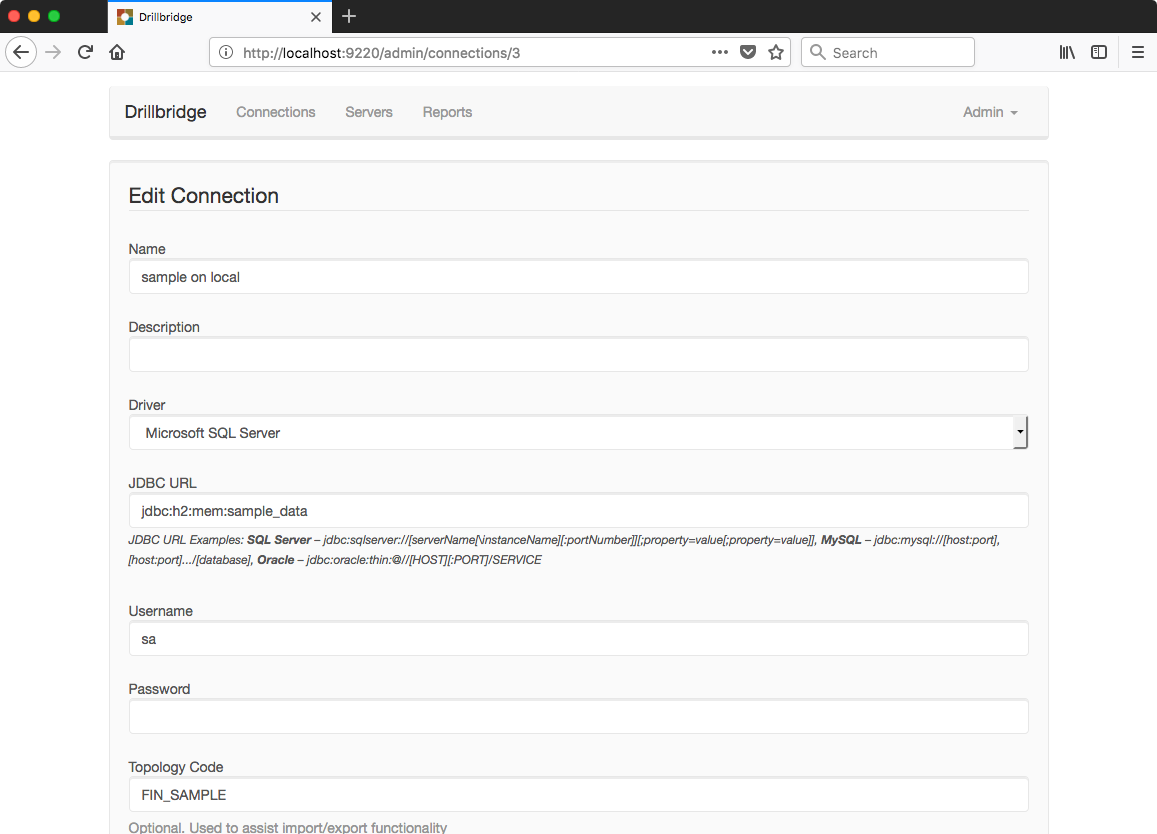
Setting up H2 in-memory JDBC connection
You may notice that the Driver type says Microsoft SQL Server – it’s not actually, if you look at the JDBC URL you can see that we are specifying a JDBC URL for the H2 database. H2 ships with and is used by Drillbridge; we can setup a new instance totally in memory by using the special URL: jdbc:h2:mem:sample_data. You can replace sample_data with whatever you want. Drillbridge will inspect this JDBC URL and use the proper driver, irrespective of what the Driver setting says. That’s actually all the config we need with regard to the data source. Next, let’s consider a simple CSV text file that we’ll want to query:
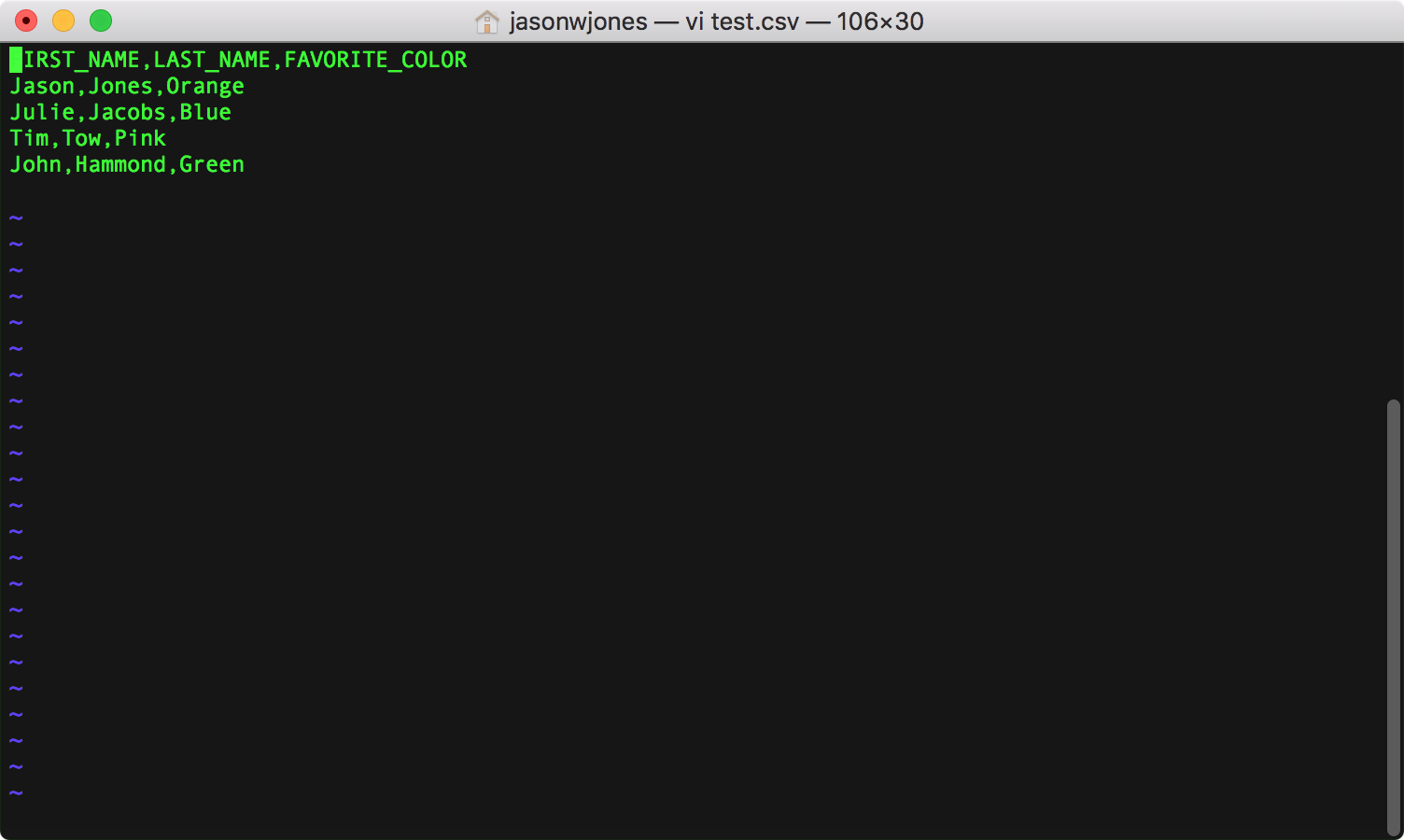
Simple CSV file with column headers (FIRST_NAME, LAST_NAME, FAVORITE_COLOR)
Note that the first row contains the column titles/field names. This isn’t strictly required but it’ll make life much simpler in a moment (because we can treat those as column names in our query). Now we can head over to the new report definition. To make this work, we’ll use H2’s built-in CSVREAD functionality. As a pedantic matter, note that I said functionality, not function. That’s because we’re treating the CSV file basically as a totally dynamic table, as opposed to having to import it upfront, all at once.
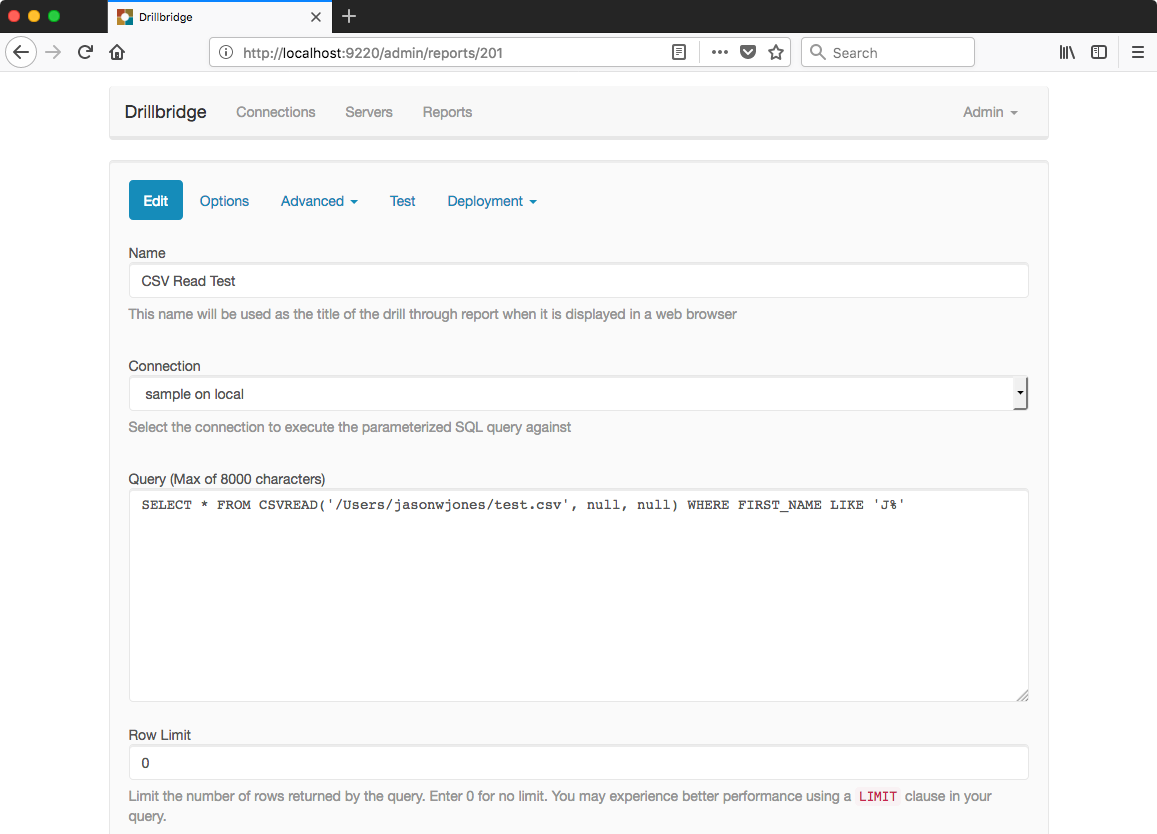
Defining the Drillbridge query to read from CSV file (CSVREAD), also with LIKE clause
You may further notice that I put a WHERE clause in, just to show that totally normal SQL filtering works exactly how we expect it to. For reference, here’s the full query: SELECT * FROM CSVREAD('test.csv', null, null) WHERE FIRST_NAME LIKE 'J%'. I’m running this just from my laptop which is why you usee the full file name in the screenshot pointing to a file in my home directory, but in principle, any file that the Drillbridge Java process can read should work just fine. Even, theoretically, a file off of a network share (although performance would go down a little bit).
Next I’ll set a few basic report options. I don’t really need to set these to make things work, but it shows off some of the flexibility that Drillbridge has in terms of formatting the output nicely. I’d like Drillbridge to slice in a new column with an auto-generated row number, title this column with “#”, and use the modern “Prophecy” theme that makes Drillbridge blend in very nicely with Oracle’s livery, as it were:
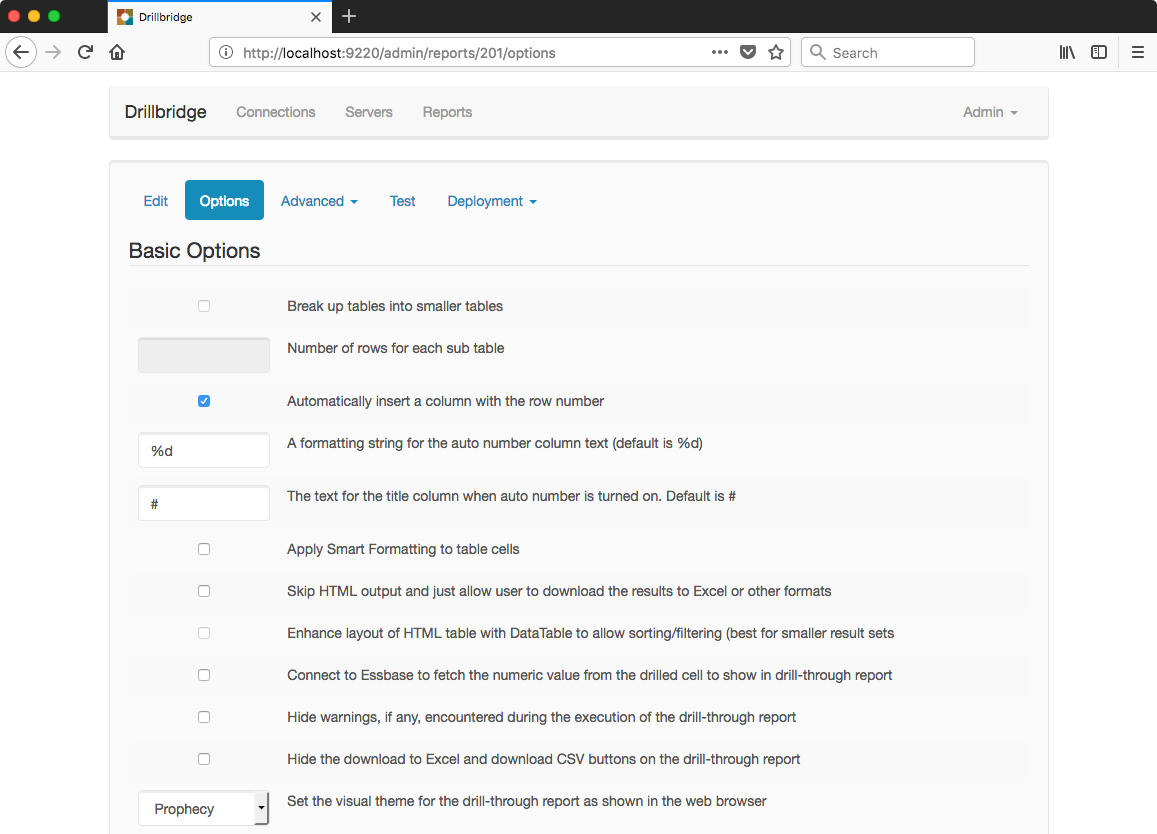
Setting some options on the output
Now to save the report definition and proceed to test it:
Test page
There are no tokens in this test (although they work just fine as always), so we can just press the Build It button and test things out:
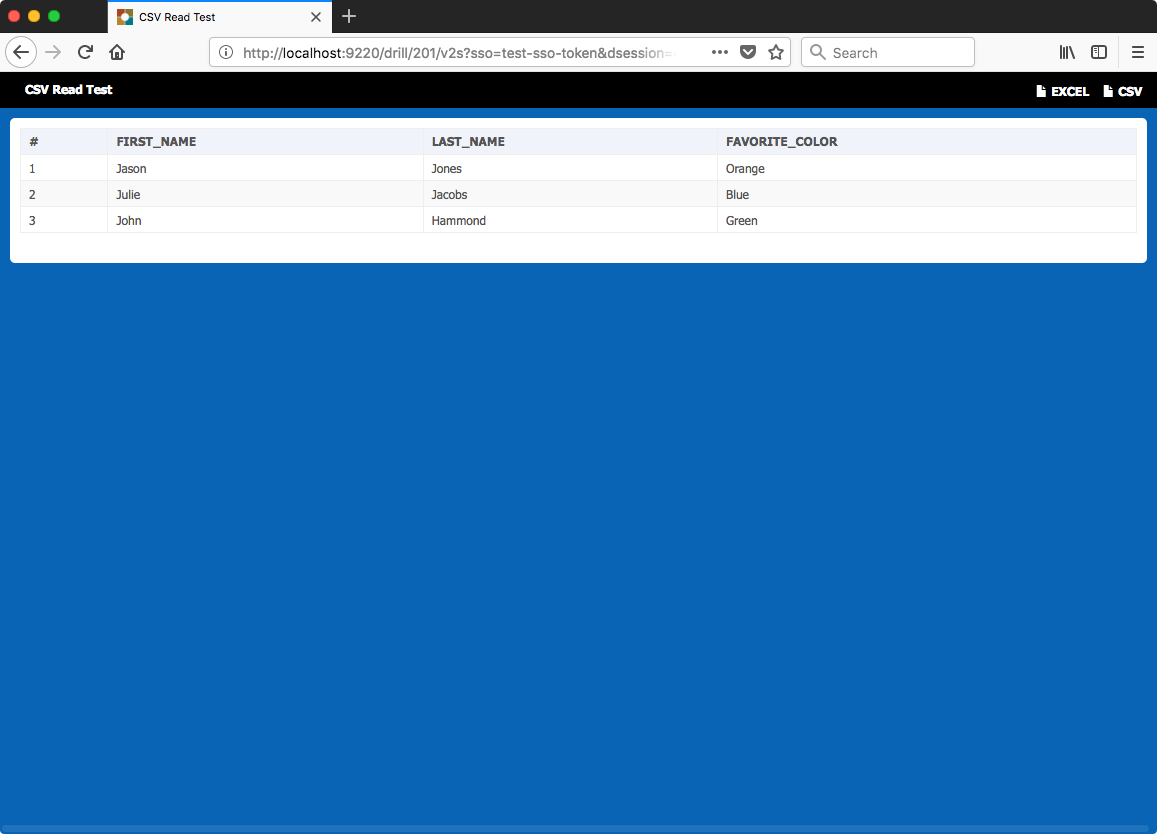
Result of testing
Sure enough, things work exactly as expected, and the data was filtered perfectly as well (in this case, only showing rows where the FIRST_NAME starts with the letter J). And just for completeness, let’s download as CSV to test what we get:
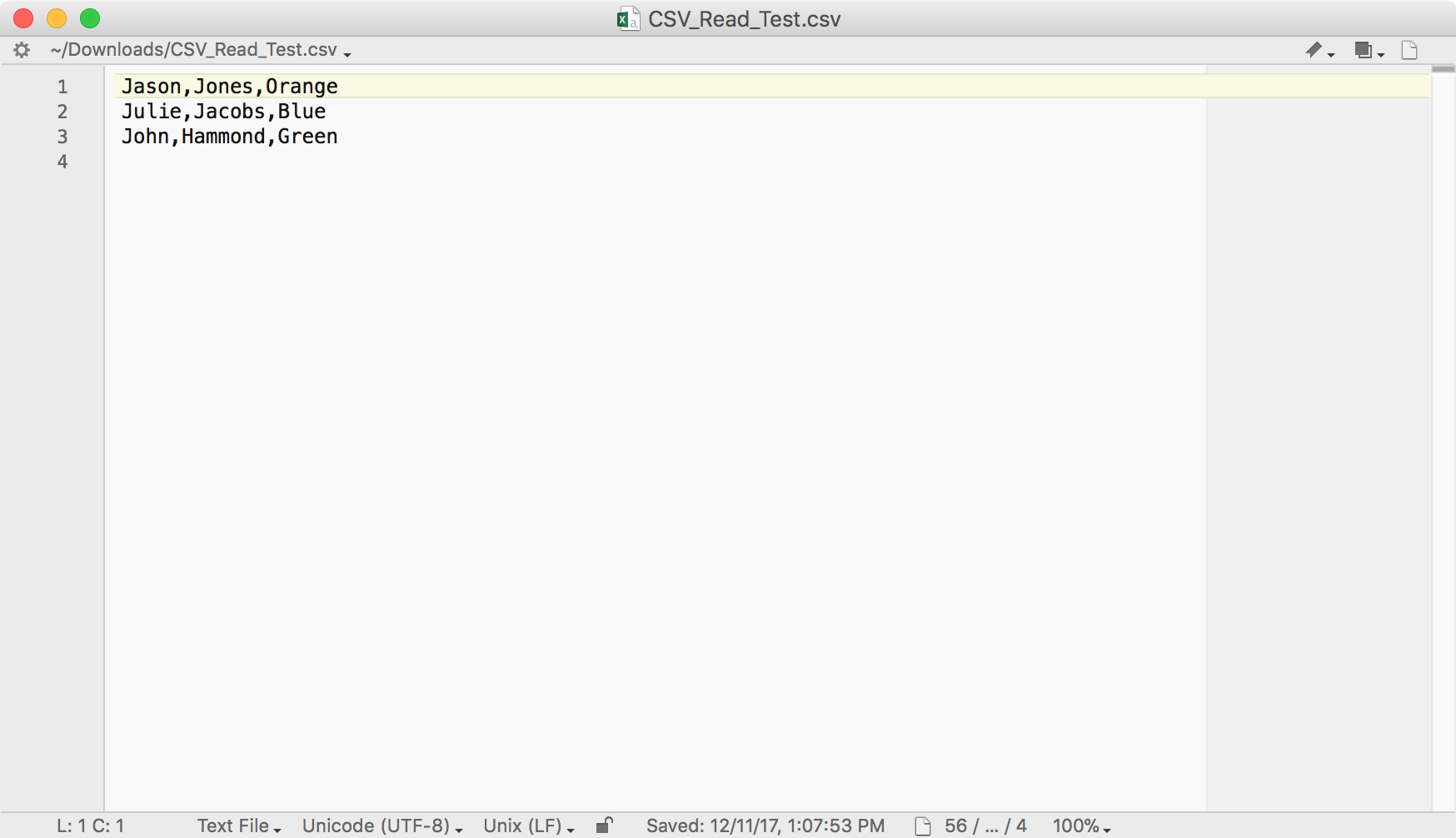
Output when downloading to CSV file
And let’s also download to Excel to validate as well:
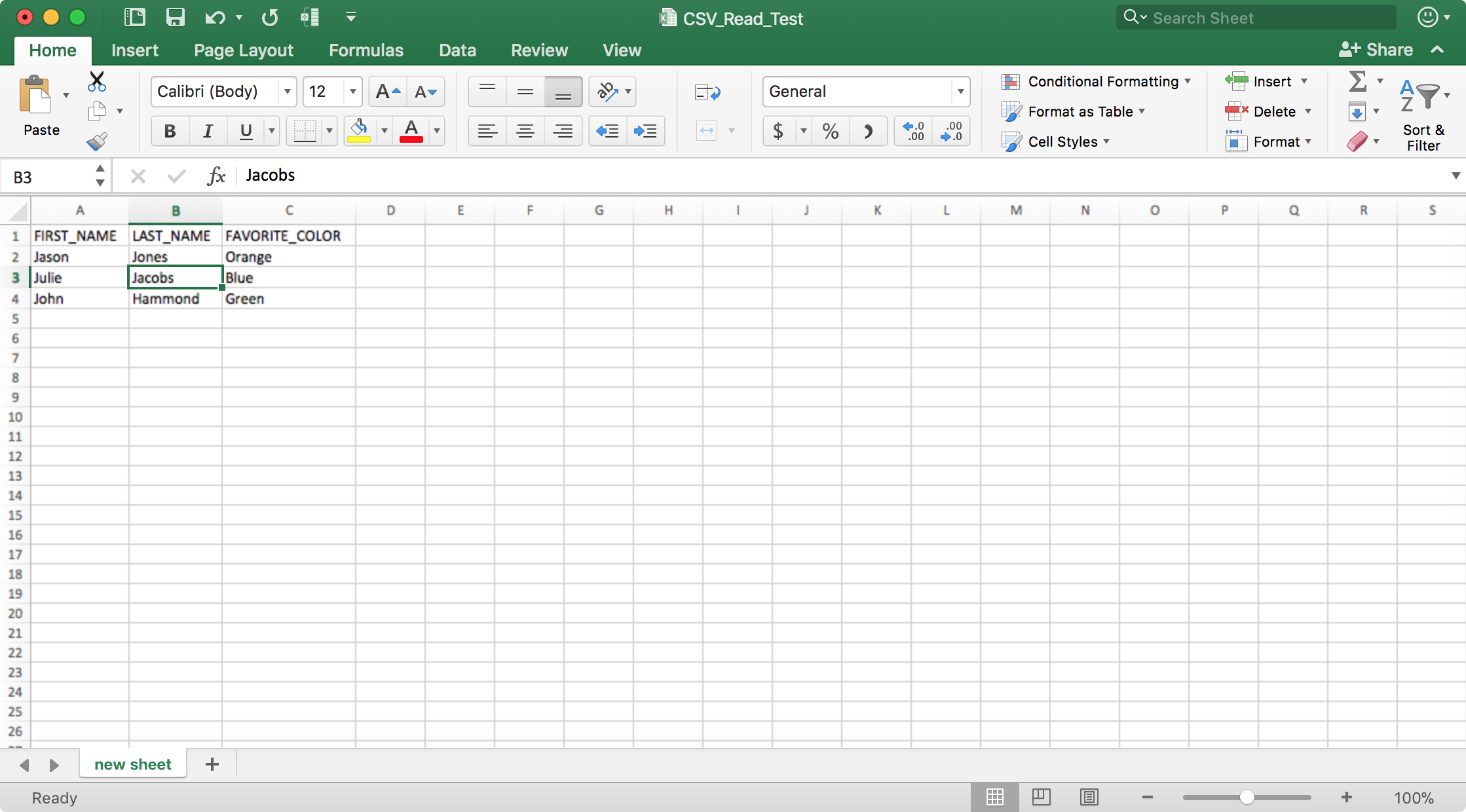
Output when downloading to Excel file
You might think that we are achieving Inception-style levels of recursion by downloading a CSV file by way of JDBC by way of another CSV file, but remember that the output has been filtered according to our query. And further: the data is now available via true drill-through (after deploying the drill-through definitions to Essbase of course)!
Performance Notes
I tested this with a real-world CSV file with over half a million rows. Returning the entire file takes about 15 seconds on my machine. I think this is mostly normal page rendering time as opposed to the CSV reading process taking an inordinate amount of time. When I narrow down the query with three WHERE clauses and have 144 output rows, the drill-through results come back in about a second – so the performance even when scanning a somewhat large CSV file seems quite acceptable and even on-par with a traditional relational database.
Misc
There are some additional options on H2’s CSVREAD functionaliy that can give you more control over how the CSV file is read and parsed, in case you need more flexibility with delimiters, newline characters, and things like that.
Summary
I hope you enjoyed this “off the beaten path” Drillbridge use case. In principle, this should work out of the box with both the free (Community Edition) of Drillbridge as well as the licensed version, Drillbridge Plus. Although the ideal drill-through situation might be one where a true relational database is being queried, I know from experience that there are a non-trivial amount of workaround solutions out there, such as like this one that uses Access, that could be quickly and easily upgraded to something vastly more user-friendly and agile. Please don’t hesitate to reach out if you have any questions.