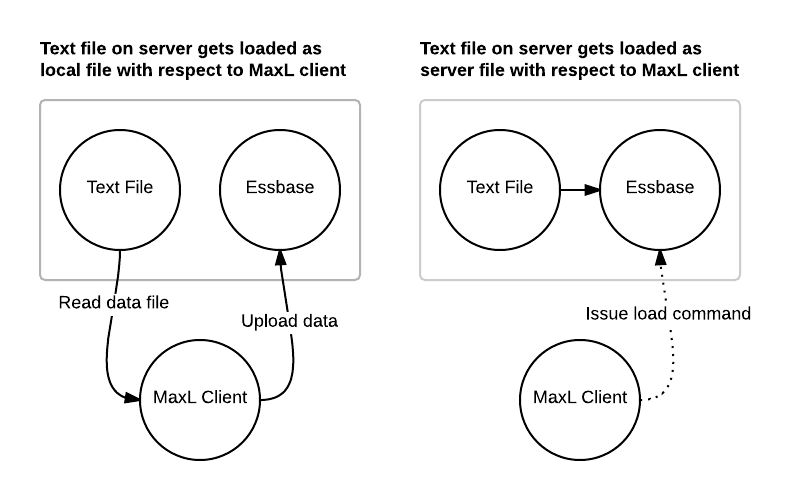
No, Quadruple Backslashes is not a college rock band (that I know of). But maybe it should be one. Anyway, ever see a quadruple backslashes on a path in a batch file? Like this:
SET FILE=\\\\some-server\\path-to-app-folder\\app\\data.txt
What’s going on here? This is a UNC path, and the normal form is like this:
SET FILE=\\some-server\path-to-app-folder\app\data.txt
Let’s say we are doing a data import in a MaxL script:
import database Sample.Basic data
from data_file "$FILE"
using server rules_file "LdAll"
on error write to "errors.txt";
In many scripting languages, backslashes are special. They are used to “escape ” things inside of strings. What if you need a newline inside of a string? That’s \n. What if you want a tab? That’s \t. What if you want to print a backslash itself? You can’t just put a single backslash in because then the interpreter thinks that the next character is something special. So to write out just a backslash you escape a backslash itself (so it’s \\).
To further complicate things, many scripting languages have a notion of interpolated and non-interpolated strings. That means that strings contained inside of double quotes (“This is a double quoted string!”) have their contents parsed/scanned for special characters. Strings in single quotes don’t (‘This is a single quoted string!’). So in the single-quoted string, we can sometimes (not always) get away with doing whatever we want with backslashes. But if we use the single quoted string we can’t stick variables in it.
So now we need a double quoted string so we can put variables in it, but this makes putting in backslashes for our UNC path a little complicated. No worries – just escape the backslashes. Returning to our quadruple backslashed MaxL example that is surrounded with double quotes, what’s happening is that MaxL parses the string contents (the stuff between the double quotes) and the four backslashes become two backslashes in the final string. The double backslashes in the other parts of the UNC path get translated into a single backslash.
The final resulting string has the two backslashes to start the UNC path and any other path delimiters are just single backslashes.
Normal Paths
If you are just loading a file from a normal, non-networked path (or it’s a mapped drive), and you’re on Windows, then I highly recommend just using forward slashes to delimit the path. For example, consider an input file at D:\Hyperion\data.txt. Your double quoted string would be D:\\Hyperion\\data.txt, which gets translated down to just single quotes. For the last decade or more, Windows has had awesome support for the more traditional forward slash Unix path separator, meaning you can just use D:/Hyperion/data.txt. The forward slash isn’t special at all so you don’t need to escape it. You can’t use double forward slashes to denote a UNC path, though, so //server-name/path/to/file.txt will not work, thus requiring some backslash kung foo to get working.
{kind=link}