Normally I finish some programming and then throw it over the wall to you guinea pigs enthusiastic blog readers before I say anything about it (no vaporware here, nosiree!), but I thought I’d share something I’ve been playing with as a proof of concept. It’s sort of inspired by some of the ODI/Essbase integration I’ve been working with lately.
The Essbase/Hyperion knowledge modules in ODI are sort of different from typical knowledge modules because in a lot of ways they cram a round peg into a square hole. So you kind of get this relational facade over an Essbase cube in terms of loading and integrating data/metadata. Instead of relying on a normal JDBC driver, the Hyperion KMs more or less delegate out to some custom Java code that wraps the Essbase Java API. This isn’t a bad thing, it’s just how it works.
Unrelated to ODI, there are many situations where we are jumping through hoops to get data of some kind – not just cube data and metadata – out of Essbase. For example, you run a MaxL script to dump stats from a cube to a text file. Then you run some regular expression voodoo on it to get to the data you actually want.
Side note: parsing MaxL text output is surely amusing to the boffins at Oracle that designed it. I don’t think many people know this, but MaxL communicates with the Essbase server using a hacked up JDBC driver (it’s ingenious really). So when we parse the plusses and minuses and other ASCII crap off of some MaxL output, effectively what is happening is that a real dataset is coming back from the Essbase server, the MaxL interpreter is applying the extra work of prettying it up with some text art (the only thing missing is lime green letters from the 80’s), it gets dumped to a text file, and then what happens in so many places is that the text is reparsed into data.
To some extent the MaxL Perl and Essbasepy modules can be used to get MaxL data in a cleaner way. The Java API can definitely be used. Of course, I have no problem myself jumping in and coding up a Essbase Java API routine to pull some data down. But for people that aren’t as comfortable, stripping some info out of MaxL output offers a clear path with less resistance, so I can’t say I blame them.
So we have all of these instances where we can get data out of Essbase (not just actual cube data, but metrics from the server) using EAS, using MaxL, dumping MaxL to a text file, the C API, Java API, and so on. But it seems like a lot of these approaches have undesirable combinations of effort/quality/reward.
Let’s talk about JDBC for a moment. JDBC is the Java Database Connectivity model. Java is one of the most popular programming languages on the planet (perhaps not the sexiest language, but it’s getting better), and JDBC is the tried and true model for connecting to databases. Every popular database in the world has a JDBC driver – you can grab a generic SQL tool (I’ve been using the simple RazorSQL as of late), pop in the appropriate JDBC driver (such as for MySQL, Microsoft SQL Server, Oracle, DB2, whatever), connect, and start issuing SELECT statements to your heart’s content.
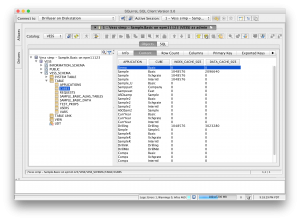
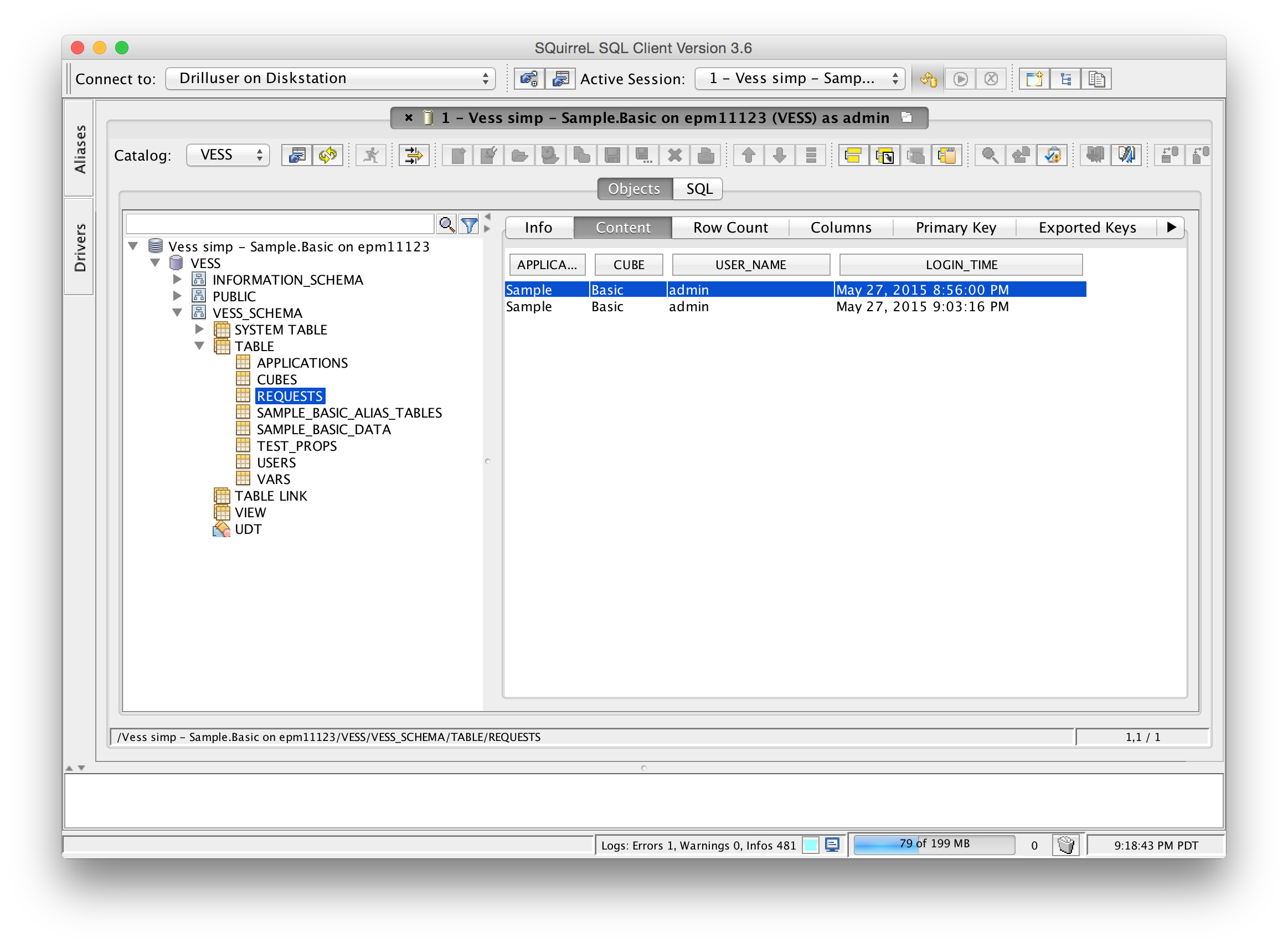
So, this all brings me to something interesting I’ve been playing with for awhile: Vess – a virtual Essbase JDBC driver. Vess is a JDBC-compliant driver that can be dropped into any generic SQL tool that supports JDBC drivers (RazorSQL) as well as used out of the box with ODI. Vess offers a JDBC-compliant URL for connecting to Essbase, such as the following:
jdbc:essbase://epm11123.corp.saxifrages.com:9000/Sample.Basic;mode=embedded
Vess then presents several tables, views, and stored procedures. For example, consider substitution variables. These are modeled in a table where the column types are String, String, String, String (the VARCHAR database type). So you can do this:
SELECT * FROM SYS.SUBSTITUION_VARIABLES
And you get back a dataset kind of like this:
Sample, Basic, CurrMonth, Jan
(It’s not actually text with commas, it’s a normal dataset). There are similar tables with other system/cube information in them, such as database stats, connected users (the Sessions tab in EAS), and more. There are views for dimensions/members/aliases/UDAs. There are stored procedures for calling calc scripts (e.g. sp_exec_calc(‘CalcAll’)). MDX queries can also be crammed into a normal JDBC ResultSet with a little bit of imagination.
So, why bother?
Using a JDBC driver would let us easily (and cleanly) get to Essbase data and metadata using any generic database tool, as well as being able to drop the driver right in to ODI and use it as part of a normal interface. Whereas ODI uses Jython to call custom Java classes, this could potentially simplify the layers a little bit and offer an interesting alternative. This could also potentially be used in places where MaxL output is being parsed out via black magic, obviate the need for writing custom Essbase JAPI programs, and some use cases with the outline extractor.
Status
As of right now, the framework of the driver is created already and you can drop it into a SQL tool such as the aforementioned RazorSQL and run a command like SELECT name FROM SYS.SUBSTITUTION_VARIABLES WHERE APP = 'Sample' and get the proper results back. Over time (as time permits) I will be adding a few more gizmos. If there are any intrepid Java developers out there that would like to play with this, let me know and I can make this an open source project on GitHub that could be refined over time.
{kind=link}