Some time ago, I reviewed and revamped the MaxL automation for a client. One of the major performance gains I got was actually pretty simple to implement but resulted in a huge performance improvement.
Did you know that the MaxL import data command can can be told whether the file to load is a local data file or a server data file? Check out the MaxL reference here for a quick refresher. See that bold “local” after from? That’s the default, meaning if we omit the keyword altogether, then the MaxL interpreter just assumes it’s a local file.
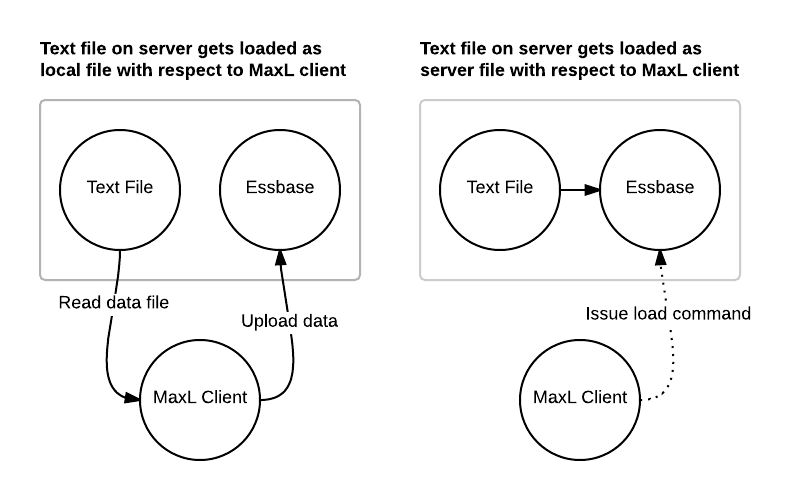
Imagine that you have an Essbase server, and then a separate machine with the MaxL interpreter. This could be your local workstation or a dedicated automation server. Let’s say that there is a text file on your workstation at C:/Essbase/data.txt. You would craft a MaxL import command to import the local data file named C:/Essbase/data.txt. That’s because the file is local to the MaxL interpreter.
Now imagine that the file we want to load is actually on the server itself and we have a drive mapped (such as the Y: drive) from our workstation to the server. We can still import the data file as a local file, but this time it’s Y:/data.txt (Assume that the drive is mapped directly to the folder containing the file).
In this scenario, MaxL reads the file over the network from the server to the client, then uploads that data back to the server. This data flow is represented in the figure in the left of this diagram:
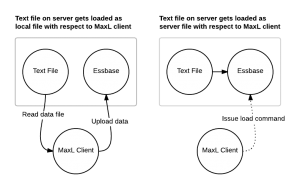
You might be thinking, “But wait, the file is on the server, shouldn’t it be faster?” Well, no. But there’s hope. Now consider server file loading. In this case we use the server keyword on the import statement and we specify the name of the file to load. Note that the file location is based on the database being loaded to. If you’re loading to Sample Basic, then Essbase will look in the ../app/Sample/Basic folder for the file. If you don’t want to put files in the database folder, you can actually cheat a little bit and specify a path such as ..\..\data.txt and load the file from a relative path. In this case by specifying the ..\..\, Essbase will go up two folders (to the \app folder) and look for the file there. You can fudge the paths a little, but the key is this: Essbase will load the file from itself, without the MaxL client incurring the performance penalty of two full trips of the data. This is depicted in the right figure in the diagram: the MaxL client issues a data load command to the server, which then loads the file directly, and we don’t incur the time needed to load the file.
In my case the automation the written to load a file that was already on the server (in the \app folder), so I just changed the import to be a server style import, and immediately cut the data import time dramatically.
I wouldn’t be surprised if this “anti-pattern” is being used in other places – so take a look at your automation. Let me know if you find this in your environment and are able to get a performance boost!