I have developed numerous jobs with Oracle Data Integrator. I have developed new jobs that connect systems together, and I have developed jobs in ODI that replace existing jobs. There are plenty of reasons for redeveloping a solution in ODI that I have talked about before. Generally you can significantly clean things up – sometimes a little, sometimes a lot.
Sometimes a very particular aspect (such as a certain section of script code) of an existing batch job will be targeted for replacement with something developed in ODI. Let’s say that there is an existing batch file that performs a series of six distinct steps (not counting boilerplate code like setting some variables and echoing out logging statements and such). For example, the steps might be this:
- Copy a file from one place to another (such as from an “incoming” folder to a known folder to another location)
- Run a custom program to process the text file in some way, generating a new file
- Use a command-line SQL program to run a particular line of SQL, to truncate a particular table
- Run a custom program (or a
BULK INSERT) to load the text file to a SQL table
- Use command-line program to run a line of SQL such as an UPDATE on the newly loaded data (
UPDATE STAGING SET YEAR = '2015' WHERE YEAR IS NULL or something)
- Run a MaxL script that clears a cube, imports data via a load rule, and calculates the database
The Perfect Solution
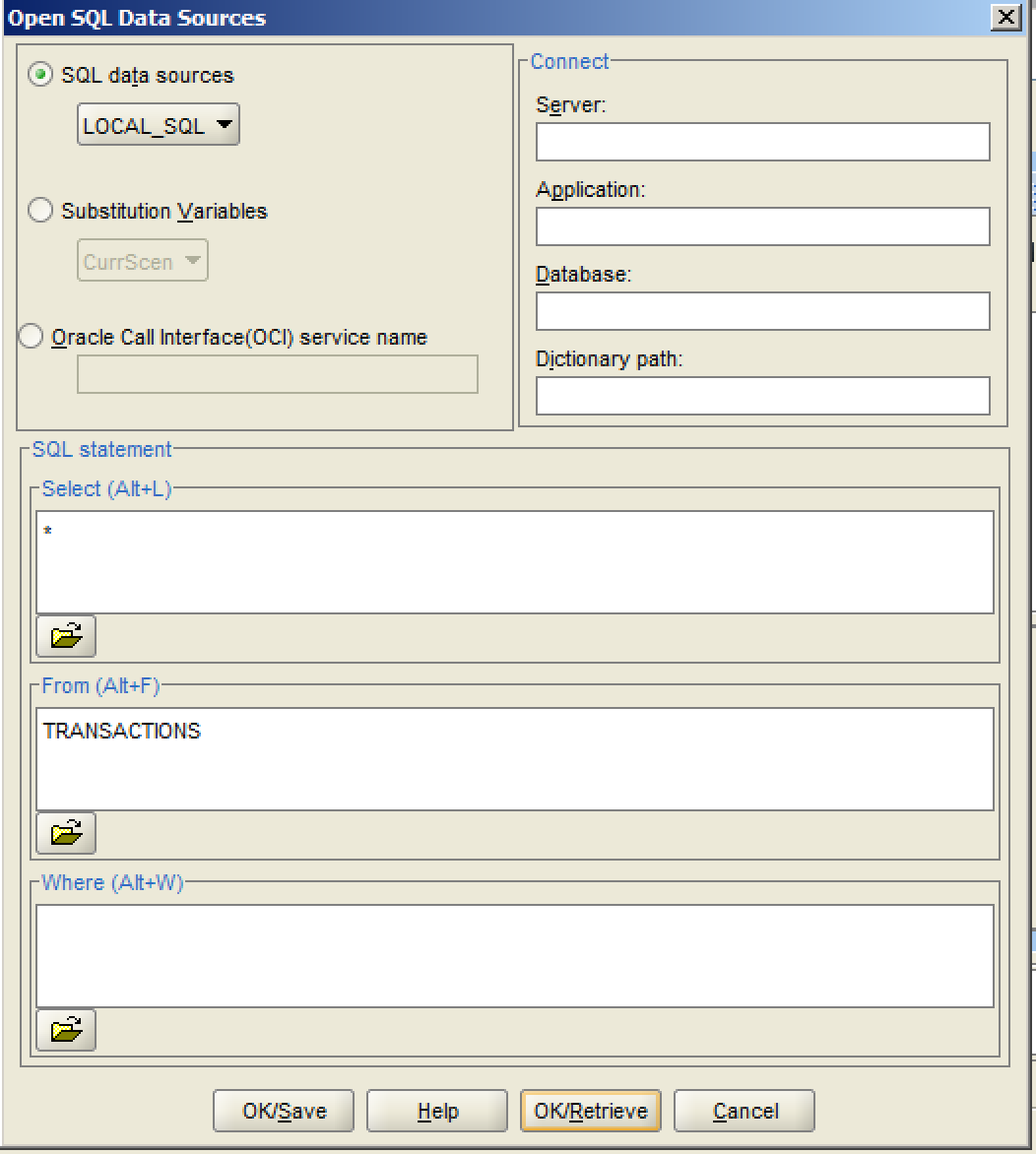
Now, sitting from my architectural ODI ivory tower, I would make the case that this should all be done in an ODI job with an interface. For example, loading a text file to Microsoft SQL Server, defaulting some of the years data, and loading the data to a cube could all more or less be done in a single interface (BULK INSERT LKM, Hyperion Data Load IKM, use appropriate load rule, etc.).
The Intermediate Solution
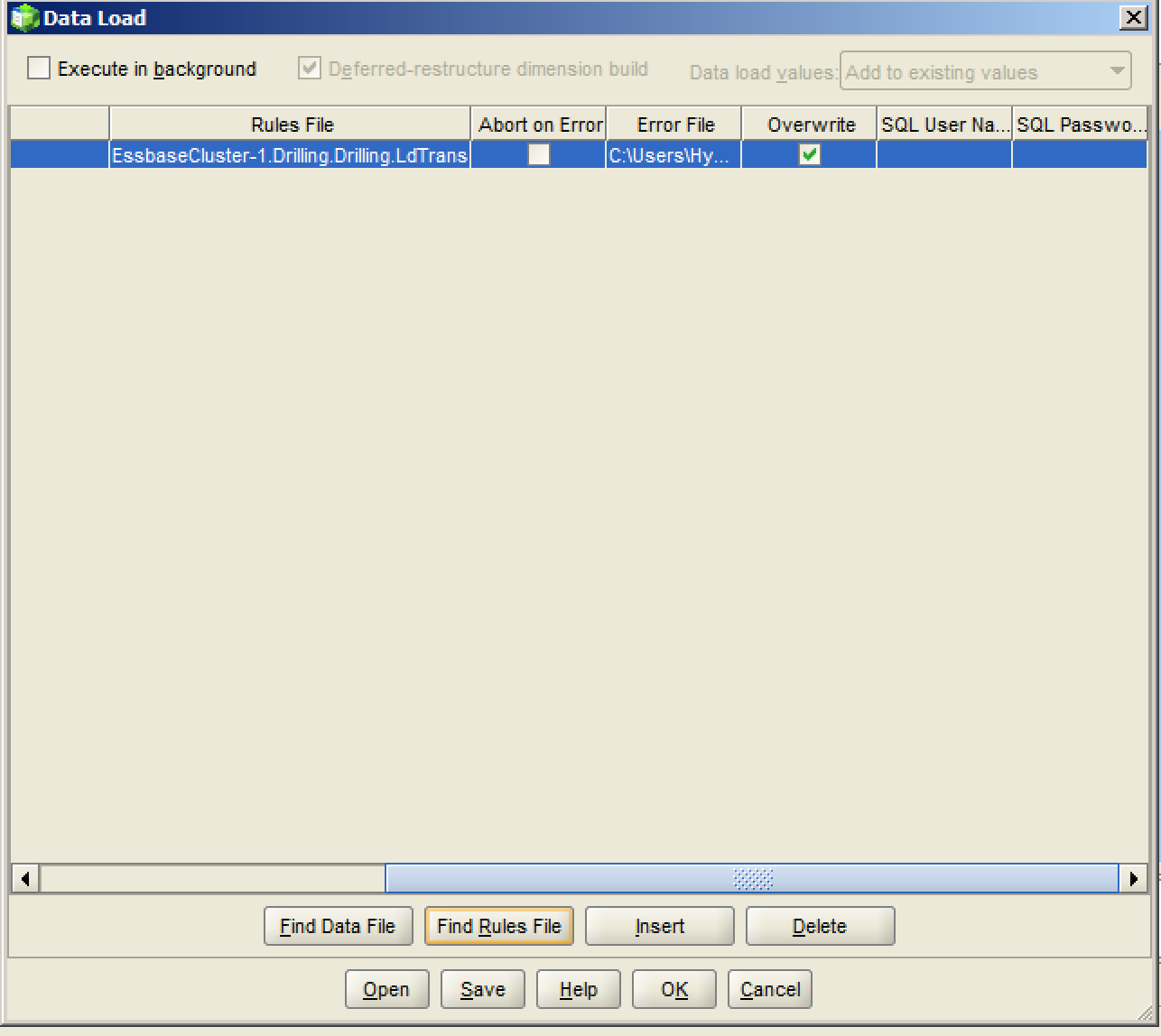
But let’s say that just the data load and nothing else is to be performed by ODI because we are revamping some of the job, but not the whole job, for some reason (risk, time, money, incrementalism). This means that we are going to call an ODI job from an existing batch file. We will use our trusty friend startscen.bat in order to accomplish this. startscen.bat is good for running scenarios. We pass in the name of the scenario, the ID, and the context so that we can very specifically ID the exact job for the ODI server to run.
So now we’ll keep our existing batch file and most of its contents, but in place of part of the previous code, we’ll have a call to startscen.bat and then resume any necessary processing after that. So technically, we’ve improved the process a bit (hopefully) by using ODI for part of it, but we haven’t really done much to significantly improve things. This is now where I get to the point of the article: I say go all in with your ODI automation.
Think of this intermediate solution like this, in terms of script code:
- Copy file from incoming folder
- Run custom program to transform file
- Call startscen.bat (invoke ODI scenario, load SQL data, load to Essbase)
The benefits of this incremental approach should be obvious: we’ve ostensibly cleaned up part of the job. Here’s the thing though: I think we’ve actually added some undesirable technical debt by doing it this way.
Yes, the job technically works, but think about how this batch file is positioned from an administration point of view now: we have a batch file, some configuration settings for that batch file (server names, encryption keys, folder paths, etc.), the batch file is likely outputting data or otherwise logging things to a text file, then we’re calling the ODI job itself, thereby creating an entry in the ODI Operator (which is a good thing, but it will only show part of the the overall job).
More often than not when I am redeveloping an automation process for someone, the batch files have no error control and inconsistent amounts of logging. The logging that is done is often times never looked at. Having easy visibility into our automation processes, however, is a very good thing. We can achieve this with ODI. While incrementalism has its merits, I say go all in with the ODI automation.
Go all in
What I mean by this is that instead of sticking with the batch file, instead of the batch file calling the automation steps and then calling an ODI step, use a package in ODI to call the necessary steps, your interfaces, and any other processing you need.
You get a lot of benefits from this approach. The ODI Operator will log each step so that you know how long each one took. You can get consistent and easy error handling/branching in an ODI package. You can easily log all of the output. You can schedule the job from the ODI scheduler. ODI has package steps that can be used to replace kludgey code in a batch file. For example, there is an ODI “wait for file” step that waits around for a file to show up. You can copy files around, pull files from FTP, and more – if you need to just call an arbitrary program or script you can do that with an ODI OS Command. Everything you need is there, and more.
You don’t even have to use the ODI scheduler. If you are already invested in another scheduler (Windows Scheduler, cron jobs, etc.) and want to keep everything in one place, then just call the ODI scenario from your scheduler, but that scenario will have been generated from a package that has all of the steps in it (instead of your batch file calling those).
This new world of pure ODI jobs is worth the extra effort to get to: you have status and metrics for all of your jobs (without tons of boilerplate logging code), you can manage your entire job in one place, and its easier to follow best (better) practices with development. While batch files and various scripts have served us well over the years, more and more I find myself abstracting away from the file system when it comes to automation and given the capabilities of ODI. It’s worth it.