There’s a lot of excitement in the EPM world these days when it comes to REST APIs – and rightfully so. As a developer heavily invested in the EPM space I am excited about some of the possibilities these new APIs offer – and what they will offer in the future. But all of this great new REST API stuff can be quite daunting – how does it work, why should you care, where does it fit in with your overall architecture, and so on. And with ODTUG‘s Kscope18 just around the corner I thought it might be useful to write a primer – or a crash course of sorts – for the EPM professional on what all this REST API business is about. Also be sure to check out one of my presentations at Kscope this year as I will be discussing the OAC Essbase REST API, how to use it, what it does, and more. Continue Reading…
Category Archives: open-source
Hyperion Parent Inferrer Updated (after four years!)
I had a need for the Hyperion Parent Inferrer functionality for an internal project I am working on. It didn’t quite do what I needed out of the box so I updated things a bit. As quick background, the Hyperion Parent Inferrer is a simple one-off Java program/library I developed (apparently four years ago, wow) to parse indented data into an explicit parent/child file.
There are a few (apparently rare) cases where this is useful. In my case, I was modeling some hierarchical data and I find the indented format to be much easier on the eyes. Like so:
Time Q1 January February March Q2 April May June Q3 July August September Q4 October November December
But when it comes time to load in to Essbase, clearly we need something more explicit. The Hyperion Parent Inferrer takes that preceding as input and then outputs something like the following:
,Time Time,Q1 Q1,January Q1,February Q1,March Time,Q2 Q2,April Q2,May Q2,June Time,Q3 Q3,July Q3,August Q3,September Time,Q4 Q4,October Q4,November Q4,December
The program has been enhanced to allow for a custom indentation character (such as tabs), to be able to specify the text rendered when there is no parent (instead of null), and a couple other little cleanups.
Hyperion Parent Inferrer is free, open source (Apache Software License version 2), and can be run as a standalone command-line Java program or as a Java library that can be incorporated into a typical Java program. The updated code is available at the Hyperion Parent Inferrer GitHub page.
Oracle Open World 2016 Recap
As I mentioned a week or so ago, I made a last minute appearance at Oracle Open World this year. It was my first time attending and presenting at OOW. I actually didn’t catch too much of the conference as I only flew in on Wednesday and flew out on Thursday. Nevertheless, I had a bit of a whirlwind experience, but a very good one. While I hadn’t planned on it (I’m more of a Kscope guy), I am now looking forward to attending Open World next year.
As for the presentation I was part of, I think it went pretty well. Many thanks to Gabby Rubin of Oracle for coming up with the idea for the presentation and facilitating it. The presentation was on “Essbase Tools and Toys” and was meant to highlight, at a high level, some of the interesting things that folks such as myself are doing that involve the Essbase APIs or otherwise work with Essbase. The presentation discussed items created by me, Tim Tow, and Harry Gates. Additionally, Kumar Ramaiyer (also from Oracle) talked a bit about what’s coming with Essbase Cloud Service (EssCS).
Advanced integration with PBJ Java PBCS REST API library
This week’s blog posts are all about the upcoming Kscope16 conference and relate to the presentations I’m part of. This year I am co-presenting with Cameron Lackpour on on-premise Planning versus PBCS and talking about some different use cases. My particular focus for this presentation is how you might use the PBCS REST API with Java.
Over the last year I have put together a Java library that works with the PBCS REST API. It has the following characteristics:
- Open Source (Apache Software License version 2.0)
- Doesn’t depend on any Oracle libraries or code
- High-quality, readable, fluent API
In my opinion, all of these goals have been met. Additionally, as of today, PBJ (PBCS Java Client) is available in Maven Central. What this means is that if you or your team programs in Java and use Maven for dependency management, you are just a few clicks away from being able to use this library.
For an overview of why you might want to use PBJ and how it compares to other scripting languages you might want to use instead (such as Groovy, Python, and more), come check out the presentation!
Today, however, I want to show how easy it is to incorporate PBJ into a Java program and do something quasi-practical. So the rest of this article will be oriented towards programmers, but for those of you that have employees or teammates that would be more likely to do the programming aspects of things, keep them in mind and send them a link.
First, let’s assume we’ve already created a new empty Maven project in Eclipse. Your experience will vary if you use IntelliJ IDEA or some other IDE. In this example I happen to be using Springsource Tool Suite (STS), which is pretty much the same as Eclipse.
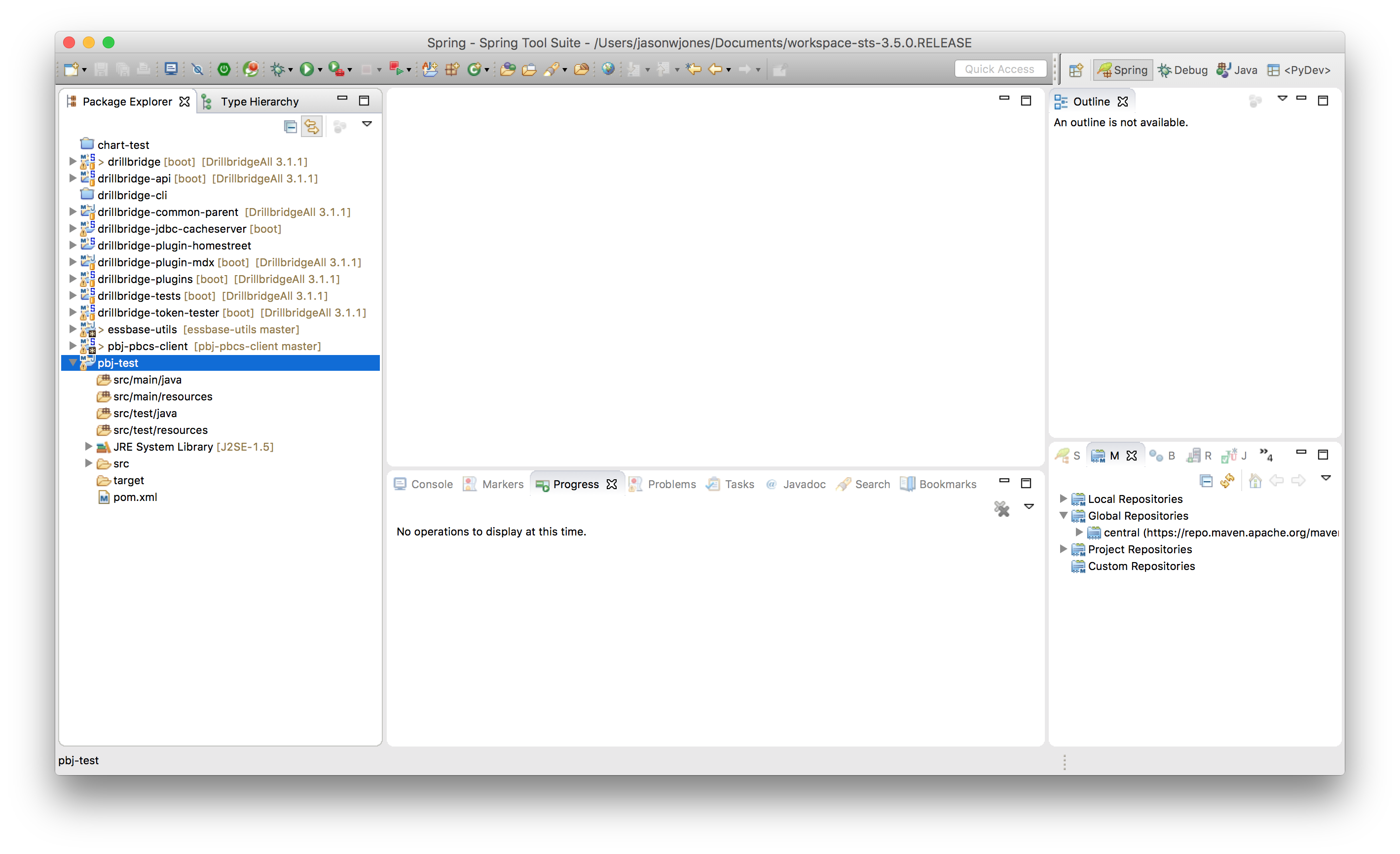
Next we need to open up our pom.xml (project definition file) to add a new dependency. You can do this manually by editing the XML file itself, but there’s a nice enough GUI in Eclipse that makes things even easier:
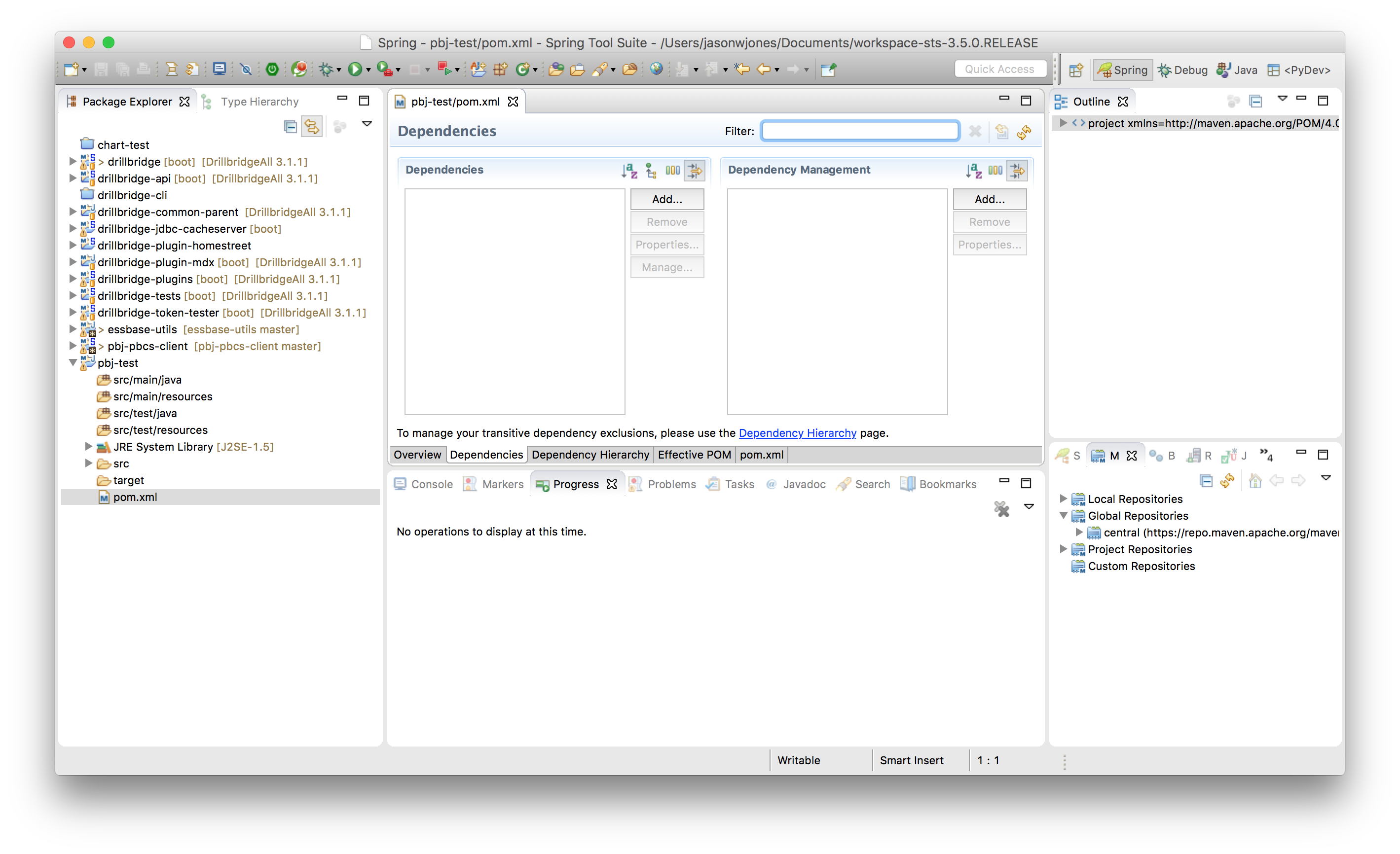
Next we need to go find the PBJ library. As I mentioned earlier, PBJ is available in the global Maven Central repository. If you have Maven set to update its index periodically or upon startup of your IDE, then you should be up to date and can find the PBJ library. As of right now the version of PBJ is just 1.0.1.
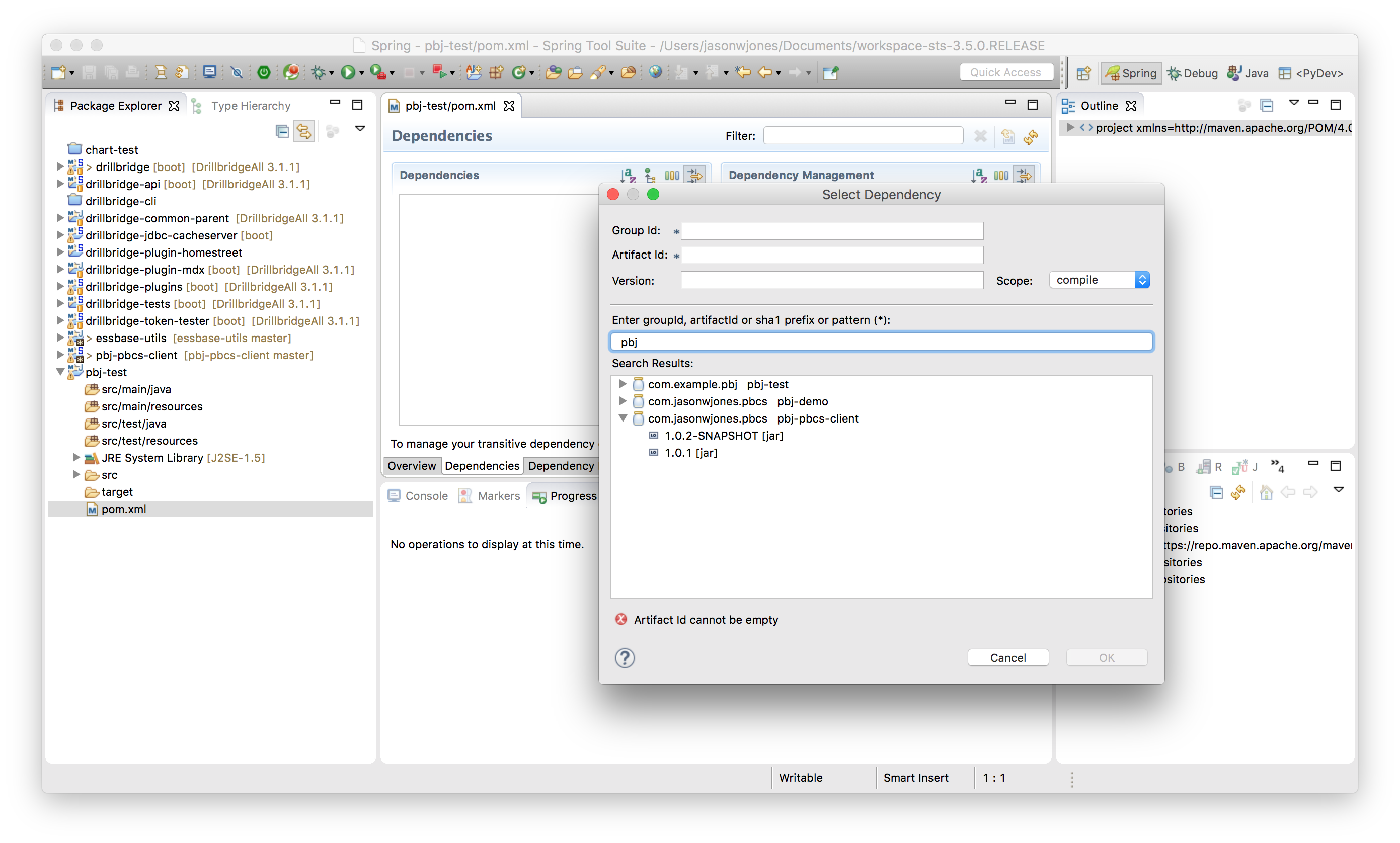
Select the library, click OK, and then save the file. The PBJ library and its dependencies are added to your project.
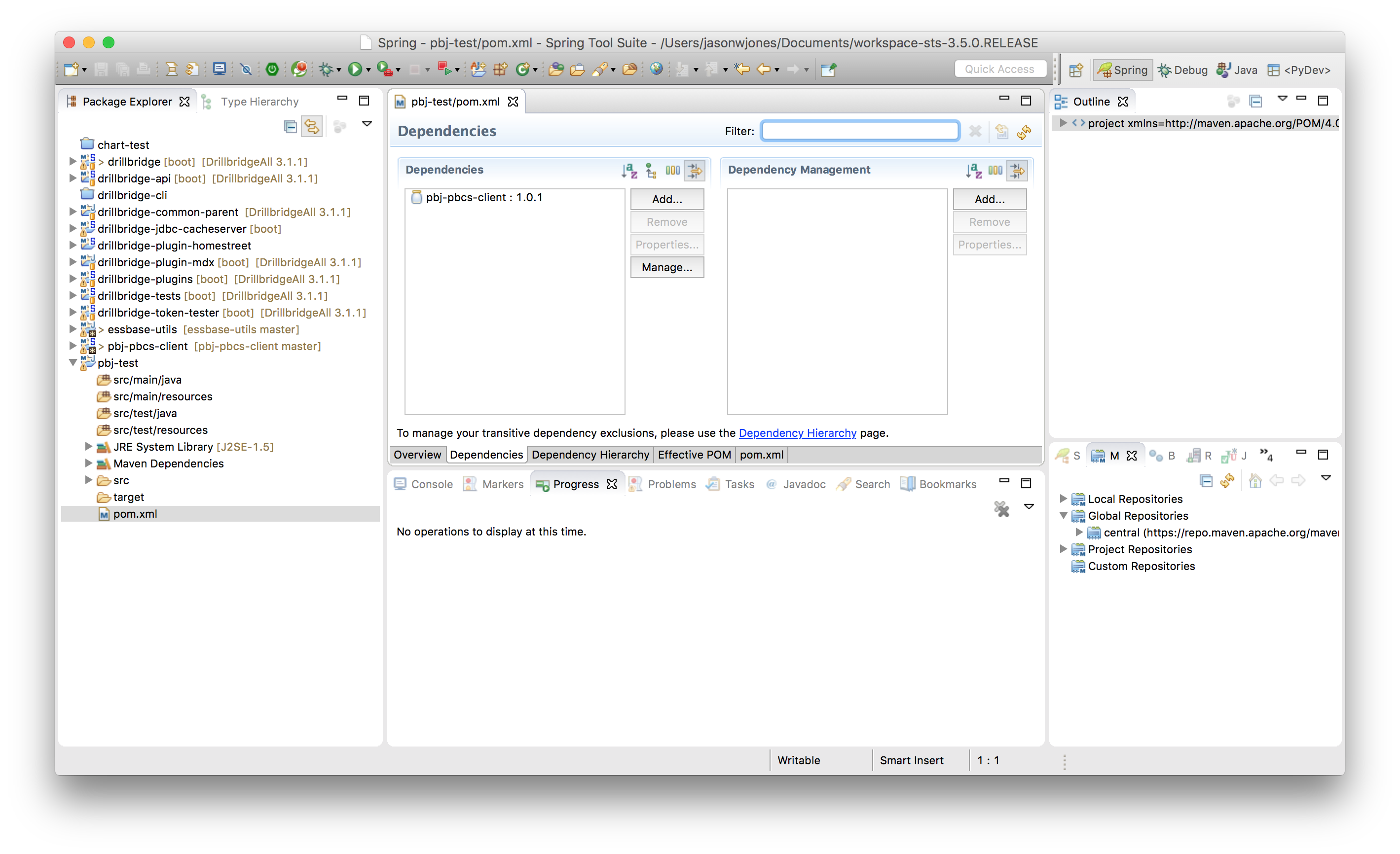
Now we can create a new main class to test things out. At this point it’s just life as normal for the Java developer:
Just for good measure (and tradition!) let’s put in a simple code to print out “Hello world”, and run it. Note the output in the bottom middle pane:
At this point we have project setup, we have all of the necessary PBJ files (and some additional transitive dependencies), and we are ready to write some Java code that uses methods in the PBJ library. The code to write is shown below:
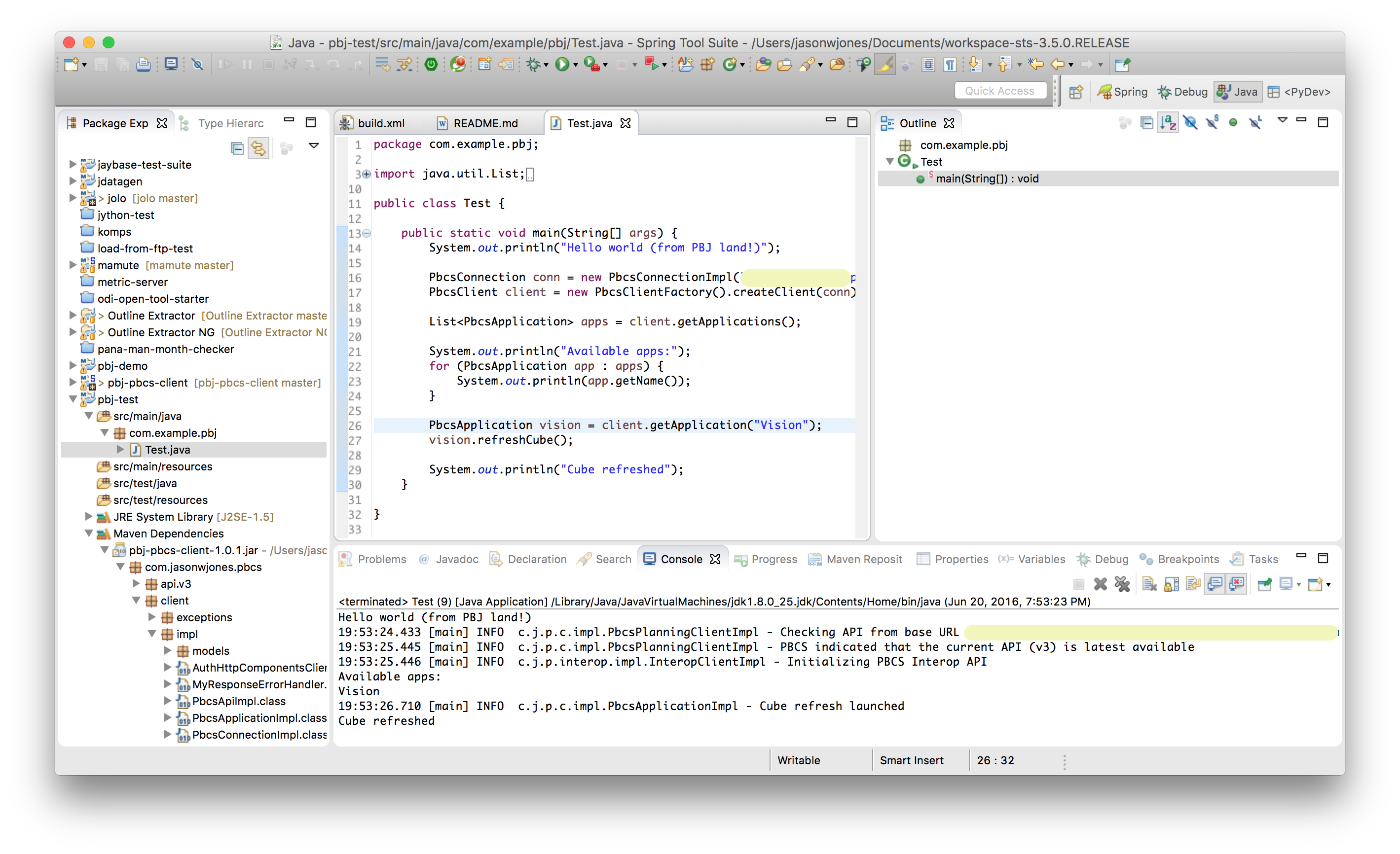
In the code you can see the following happen:
- A connection details object is created
- A connection to PBCS is made
- Ask for the list of available apps
- Print out the list of available apps
- Get a reference to a particular app (“Vision”)
- Call the refreshCube method on the app reference to refresh the cube
- Print message after cube refresh
It’s hard to imagine this code being much simpler. If might look like greek if you’re not familiar with programming or Java, but to a Java programmer, this will be readily comprehensible and its intent obvious. PBJ supports most of the REST API – importing data, metadata, business rules, and more.
To see a specific use-case and hear wry commentary from myself and Cameron, please swing by our presentation. We’ll cover an example of PBJ (don’t worry, it’s higher level than this!) but more generally some facets of administration of on-prem versus PBCS will be discussed as well. I think the presentation will really appeal to many different user groups.
Vess: a Virtual Essbase JDBC driver
Normally I finish some programming and then throw it over the wall to you guinea pigs enthusiastic blog readers before I say anything about it (no vaporware here, nosiree!), but I thought I’d share something I’ve been playing with as a proof of concept. It’s sort of inspired by some of the ODI/Essbase integration I’ve been working with lately.
The Essbase/Hyperion knowledge modules in ODI are sort of different from typical knowledge modules because in a lot of ways they cram a round peg into a square hole. So you kind of get this relational facade over an Essbase cube in terms of loading and integrating data/metadata. Instead of relying on a normal JDBC driver, the Hyperion KMs more or less delegate out to some custom Java code that wraps the Essbase Java API. This isn’t a bad thing, it’s just how it works.
Unrelated to ODI, there are many situations where we are jumping through hoops to get data of some kind – not just cube data and metadata – out of Essbase. For example, you run a MaxL script to dump stats from a cube to a text file. Then you run some regular expression voodoo on it to get to the data you actually want.
Side note: parsing MaxL text output is surely amusing to the boffins at Oracle that designed it. I don’t think many people know this, but MaxL communicates with the Essbase server using a hacked up JDBC driver (it’s ingenious really). So when we parse the plusses and minuses and other ASCII crap off of some MaxL output, effectively what is happening is that a real dataset is coming back from the Essbase server, the MaxL interpreter is applying the extra work of prettying it up with some text art (the only thing missing is lime green letters from the 80’s), it gets dumped to a text file, and then what happens in so many places is that the text is reparsed into data.
{kind=link}
To some extent the MaxL Perl and Essbasepy modules can be used to get MaxL data in a cleaner way. The Java API can definitely be used. Of course, I have no problem myself jumping in and coding up a Essbase Java API routine to pull some data down. But for people that aren’t as comfortable, stripping some info out of MaxL output offers a clear path with less resistance, so I can’t say I blame them.
So we have all of these instances where we can get data out of Essbase (not just actual cube data, but metrics from the server) using EAS, using MaxL, dumping MaxL to a text file, the C API, Java API, and so on. But it seems like a lot of these approaches have undesirable combinations of effort/quality/reward.
Let’s talk about JDBC for a moment. JDBC is the Java Database Connectivity model. Java is one of the most popular programming languages on the planet (perhaps not the sexiest language, but it’s getting better), and JDBC is the tried and true model for connecting to databases. Every popular database in the world has a JDBC driver – you can grab a generic SQL tool (I’ve been using the simple RazorSQL as of late), pop in the appropriate JDBC driver (such as for MySQL, Microsoft SQL Server, Oracle, DB2, whatever), connect, and start issuing SELECT statements to your heart’s content.
So, this all brings me to something interesting I’ve been playing with for awhile: Vess – a virtual Essbase JDBC driver. Vess is a JDBC-compliant driver that can be dropped into any generic SQL tool that supports JDBC drivers (RazorSQL) as well as used out of the box with ODI. Vess offers a JDBC-compliant URL for connecting to Essbase, such as the following:
jdbc:essbase://epm11123.corp.saxifrages.com:9000/Sample.Basic;mode=embedded
Vess then presents several tables, views, and stored procedures. For example, consider substitution variables. These are modeled in a table where the column types are String, String, String, String (the VARCHAR database type). So you can do this:
SELECT * FROM SYS.SUBSTITUION_VARIABLES
And you get back a dataset kind of like this:
Sample, Basic, CurrMonth, Jan
(It’s not actually text with commas, it’s a normal dataset). There are similar tables with other system/cube information in them, such as database stats, connected users (the Sessions tab in EAS), and more. There are views for dimensions/members/aliases/UDAs. There are stored procedures for calling calc scripts (e.g. sp_exec_calc(‘CalcAll’)). MDX queries can also be crammed into a normal JDBC ResultSet with a little bit of imagination.
So, why bother?
Using a JDBC driver would let us easily (and cleanly) get to Essbase data and metadata using any generic database tool, as well as being able to drop the driver right in to ODI and use it as part of a normal interface. Whereas ODI uses Jython to call custom Java classes, this could potentially simplify the layers a little bit and offer an interesting alternative. This could also potentially be used in places where MaxL output is being parsed out via black magic, obviate the need for writing custom Essbase JAPI programs, and some use cases with the outline extractor.
Status
As of right now, the framework of the driver is created already and you can drop it into a SQL tool such as the aforementioned RazorSQL and run a command like SELECT name FROM SYS.SUBSTITUTION_VARIABLES WHERE APP = 'Sample' and get the proper results back. Over time (as time permits) I will be adding a few more gizmos. If there are any intrepid Java developers out there that would like to play with this, let me know and I can make this an open source project on GitHub that could be refined over time.
Essbase Outline Export Parser released
I had a use-case today where I needed to parse an XML file created by the relatively new MaxL command “export outline”. This command generates an XML file for a given cube for either all dimensions or just all dimensions you specify. I just needed to scrape the file for the hierarchy of a given dimension, and that’s exactly what this tool does: pass in an XML file that was generated by export outline, then pass in the name of a dimension, and the output to the console will be a space-indented list of members in the dimension. More information on usage at the Essbase Outline Export Parser GitHub page including sample input, sample output, and command-line usage.
Also note that the venerable Harry Gates has also created something similar that includes a GUI in addition to working on the command line. While both written in Java, we’re using different methods to parse the XML. Since I’m more familiar/comfortable with JAXB for reading XML I went with that, which in my experience gives a nice clean and extensible way to model the XML file and read it without too much trouble. The code for this project could be easily extended to provide other output formats.
essbasepy Python MaxL module for Hyperion moved!
As some of you may know, I am now the active maintainer for the essbasepy Python module for MaxL. This project is an analog to the MaxL Perl module that was originally created by David Welden. I have put a fair bit of time into getting up and running with it, updating it, and testing it against EPM 11.1.2.3. I have now moved the code from its previous home on Google Code to an open repo on my GitHub account.
Other than moving to GitHub, I have included a few updates for the newest version of Hyperion, updated the documentation, and consolidated the distribution down to one master set of files. The future plans for this project are to keep validating it against Hyperion updates, polish it a bit, and enhance the documentation even more. At this point I don’t have any plans to significantly change the functionality.
I know there’s a handful of you out there that are hardcore users of this so if you have any issues or questions, please don’t hesitate to contact me.
Hyperion code drop: Parent Inferrer tool
I am pleased to release another small one-off Hyperion-related open-source tool into the wild: Hyperion Parent Inferrer. This Java program/library can be used to translate a space-delimited hierarchy file into one with explicit parent-child mappings. For example, consider the following input file:
Time Q1 January February March Q2 April May June Q3 July August September Q4 October November December
Hyperion Parent Inferrer will generate the following output:
null,Time Time,Q1 Q1,January Q1,February Q1,March Time,Q2 Q2,April Q2,May Q2,June Time,Q3 Q3,July Q3,August Q3,September Time,Q4 Q4,October Q4,November Q4,December
As with most of the things I release these days, this tool is just a cleaned up version of something that I needed or used once or twice. In this case I wrote this up to help with a conversion process at some time in the past.
Now, I’m not saying that the approach I had to take was ideal or there weren’t better solutions. But oftentimes the environment that we operate in is less than ideal and you just gotta find a way to duct tape everything together. Hence this tool. The code as it sits today works perfectly fine but does not provide much in the way of configurability or options that might make it useful in more contexts. But as with some of the other projects I have released, I thought it would be nice to toss this over the fence in case anyone can benefit from it.
If you find a use for this or want to show me your clever Python/Perl one-liner that does the same thing, let me know!
ADS File Reader 1.0.0 released
As promised, I cleaned up the Java code for very easily parsing through files in the ADS format. ADS File Reader has an incredibly intuitive, clean, and functional API that makes parsing through ADS files a breeze. You won’t believe how easy it is to burn through an ADS file (if you have to). I can’t imagine that there are a ton of people out there that need to do this, but if you wind up having to (and especially if you need it in a larger Java program) then you should be all set. As with most of my other projects, ADS File Reader is licensed under the Apache Software License version 2.0 and is available on GitHub. For more information and a link to GitHub, check out the ADS File Reader project page.
Thanks to all of you that sent in some ADS files that I could play with. It definitely helped flush out a couple of kinks. If you end up using this library please let me know, and definitely let me know if you run into any issues.
Do you have any ADS files you can share with me?
As you may have noticed I have a penchant for throwing my various Java and other language endeavors over the wall and seeing what happens. Most of these are open source programs ostensibly in the Hyperion Essbase space, but every day my focus seems to broaden a bit. I’ve open sourced data generators, validation tools, substitution variable updaters, and more.
The particular code that I am cleaning up now and getting ready to kick out as a small Java library for reading the ADS file format. Awhile back it was necessary for me to work with raw ADS files and use them as the input to another system. For those of you that aren’t familiar, the ADS file format is used by LCM when you kick out an EPMA dimension. I’m sure it’s used in other contexts too but this is just what I know it from. It’s not incredibly complex but it does have its nuances.
I’d like to be able to test it against some files other than some of my own, so if you have an ADS file laying around or can generate one that you can share with me so I can test with that too, I’d appreciate it. I will absolutely NOT distribute it with the rest of the program or otherwise share it with anyone else unless you explicitly say I may do so.
Thanks!