I got a call the other day from one of my fellow Essbase developers. One of the cubes in their budgeting system was taking a long time to finish calculations, whereas just days before the calculation time was just fine. I have an almost unhealthy obsession with cube performance and optimization, so I jumped in to take a look.
The first thing I looked at (although not generally the first thing I look at) was the average cluster ratio. The average cluster ratio is roughly analogous to the fragmentation of your hard drive: data gets added, removed, and the performance with regard to accessing that data is increasingly suboptimal. Although the configuration of the sparse and dense dimensions in a BSO cube in theory dictates where data gets placed in the corresponding data files, quite often, for performance reasons, the data files will just grow to accomodate the new data instead of putting it where it “should” go. A cluster ratio of 1.00 is optimal. In this case, the database with performance issues was reporting a significantly lower cluster ratio. So the first order of business was to export all of the data in the cube to a raw export file, clear the cube, then reimport.
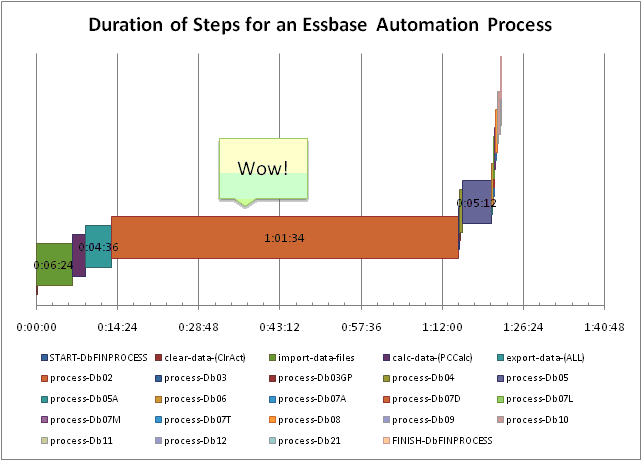
This helped performance a little bit, but not much. Something else needed to be done. I checked out the index and page files in the cube directory to discover that the index files were almost four gigabytes, with about 20 gigabytes of page files. This size of data isn’t inherently difficult to work with, but it does warrant a look into the dense and sparse dimension settings, the calc script that is having issues, and trying to understand the way in which the database data is being used.
The database is a six dimension cube with the following dimensions: Scenario, Years, Time, Location, Customer, Commodities. Time and Scenario are marked as dense. I can live with Time being dense, especially since it’s just periods rolling to quarters rolling to a fiscal year (with non-Level 0 members tagged as Dynamic Calc), but the dense Scenario dimension didn’t quit jive with me. In this particular database, it turns out that the reason for the block explosion and subsequent poor calc performance is that users and loading in tons of data to the Forecast member in Scenario. Scenario also has four other dense members. In addition to the cube being to to create blocks new blocks on equations, the size of the page files was blowing out with all of the data being sent in.
The first thing that jumps out at me is that even though all of this data is being loaded to the Forecast member, we’re taking a hit on storage because the dense data blocks are being allocated for the other four members in Scenario that are very sparingly utilized. Surely there is a better candidate for a dense dimension? You betcha. Given the sparse nature of the database, most of the other dimensions aren’t really good candidates for dense because of all the interdimensional irrelevance that it would incur, however, the Years dimension is a good candidate because the Forecast data being loaded in is being loaded in for a particular year and all periods. Perfect.
Given that there are not a significant number of calc, report, and load scripts in this database, it is relatively safe to change the dimensional configuration here. This isn’t always necessarily the case and changing dense/sparse settings could very easily deoptimize the performace of calc, load, and report scripts, not to mention adversely affecting other numerous aspects of the database.
And of course, this was all tested on the test server before loading to production. The process was fairly straightforward. I cleared the database again, and loaded the export file. Since export files are sensitive to the dense/sparse settings in the database, I did this so I could restructure the database with the new settings and have Essbase do the work for me instead of having to load the data from somewhere else. I also made sure to do this before doing a calculation on the database so there would be less data to restructure. After the data loaded in, I changed the dense and sparse settings to set Years to dense and Scenario to sparse. After the restructure, database statistics were looking fairly good, but I didn’t want to get my hopes up.
Clearly one of the issues with this database was that the calculation script that was taking too long had to span through 20 gigabytes of page files in order to do what it needed to do. Generally my databases are set to bitmap encoding as the compression scheme (because in most cases it is “good enough”), but I decided to go with zlib compression instead. Although technically speaking, zlib is more computationally intensive to compress and uncompress, because our servers’ CPUs aren’t generally getting hammered, I decided that I would rather hit the CPUs a little harder if it meant that I could read the data off the disk a little faster (even though it will still uncompress in memory to the same amount as bitmap encoding or any other compression scheme). Conversely, the stronger compression will mean less data is also written to the disk.
I then had to do some tweaking to the calc script to align it with the next dense and sparse settings. This was fairly easy. As with most calc script optimization, this involved changing the FIX statements and CALC DIM statements so that I was fixing on sparse dimensions and doing as much calculating within the dense data block as possible. Remember, you are always trying to help Essbase do its job and give it hints as to how it can do things more optimally. In this case, we are trying to minimize the amount of data that must be scanned through. By calculating within the dense blocks, we are doing all of the work in one place that we can, then moving on to the next area. For good measure, I also added a SET command to utilize the server’s higher calc lock block setting (see your technical reference for more details).
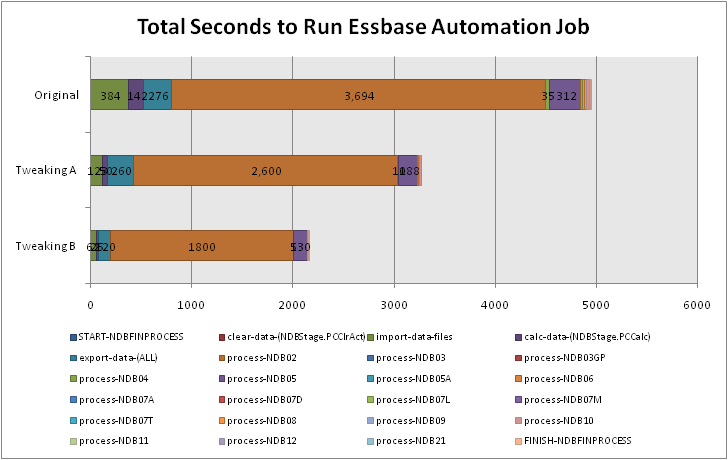
I fired off the calculation and checked out the results. The calculation’s first pass took about 20 minutes (a lot of blocks were being created the first time around). After this pass was done, I checked out the index and page files. The index file seemed to be holding steady at about 300 megabytes — quite an improvement from four gigs! The page file was now about 700 megabytes. Given this new page file size, I decided to set the index cache to 512 megabytes. Although this will eat 512 megabytes directly out of memory on the server, we have decided to allocate more memory for this app until forecasts are done, then we can pull back on the amount of memory it gets. But for now, with enough memory to hold the entire index at one time, calculations and other operations will be much faster.
At the time of this writing, the database calculation that was the original problem is still holding steady at about 10 minutes to calculate. The page and index files have grown a bit but still appear to be holding steady, and the database statistics indicate a pretty good block density as well. Not a bad bit of optimization — a twentyfold decrease in size on disk, and a calculation that comes back in minutes rather than never.
Like I said, I love performance optimization, and as I’ve said before, Essbase is a bit of an art and a science. The art part is comprehensively understanding how things work and how they are meant to work, then using that information to make the right technical tradeoffs, then putting the changes into the system, keeping in mind that you are simply trying to give “hints” to the system to help it do its job a little better or faster.