There’s a lot of excitement in the EPM world these days when it comes to REST APIs – and rightfully so. As a developer heavily invested in the EPM space I am excited about some of the possibilities these new APIs offer – and what they will offer in the future. But all of this great new REST API stuff can be quite daunting – how does it work, why should you care, where does it fit in with your overall architecture, and so on. And with ODTUG‘s Kscope18 just around the corner I thought it might be useful to write a primer – or a crash course of sorts – for the EPM professional on what all this REST API business is about. Also be sure to check out one of my presentations at Kscope this year as I will be discussing the OAC Essbase REST API, how to use it, what it does, and more. Continue Reading…
Category Archives: java
PBCS Scripting with Groovy using the PBJ REST API Library
I was talking to a colleague the other day that wants to do some scripting with PBCS using Groovy. Of course, since PBCS has a REST API, we can do scripting with pretty much any modern language. There are even some excellent examples of scripting with PBCS using Groovy out there.
However, since Groovy runs on the JVM (Java Virtual Machine), we can actually leverage any existing Java library that we want to – including the already existing PBJ library that provides a super clean domain specific language for working with PBCS via its REST API. To make things nice and simple, PBJ can even be packaged as an “uber jar” – a self-contained JAR that contains all of its dependency JARs. This can make things a little simpler to manage, especially in cases where PBJ is used in places like ODI.
For this example I’m going to take the PBJ library uber jar, add it to a new Groovy project (in the IntelliJ IDE), then write some code to connect, fetch the list of applications, then iterate over those and print out the list of jobs in each application.
Evolution of Essbase: new URL-based drill-through showed up in 11.1.1.3
Continuing on with the idea of getting insight into the Essbase feature set over time, as viewed through the lens of its Essbase Java API evolution, you can quite clearly see that the open/URL-style drill-through (as opposed to classic LRO-based drill-through) showed up in version 11.1.1.3, which in fact is pretty much the only thing that seemed to get added to this particular release, Java API-wise, along with some ancillary drill-through methods/functionality in some related classes.
More near to my heart: this is the exact functionality that paved the way for Drillbridge! Although it wasn’t available as a feature on day 1, subsequent versions of Drillbridge gained the ability to automatically deploy drill-through definitions to a given cube, and it uses exactly these API methods to accomplish it.
New webpage for Essbase Java API evolution
A fair bit of my job is dealing with and building solutions around the Essbase Java API. For many years, the Java API has been the premier way to programmatically work with Essbase (compared to say, the C and VB APIs, which have fallen out of favor). As part of this development work, it’s often important to see when (in terms of version) a certain class, method, interface, or other object has been added, modified, removed, or deprecated.
As a bit of a side project, I have been working with a library for comparing Java JARs to each other (japicmp). By processing and interpreting the results of just about every single Essbase Java JAR from 7.0.1, through the 9.x series, multiple 11.x’s, and finally to version 12.2.x, I have come up with something of a master table that shows all of these changes. You can view the initial results of the Essbase JAPI JAR evolution analysis. I’ll probably refresh this and enhance the output as new library versions become available or as I determine that additional insights become useful.
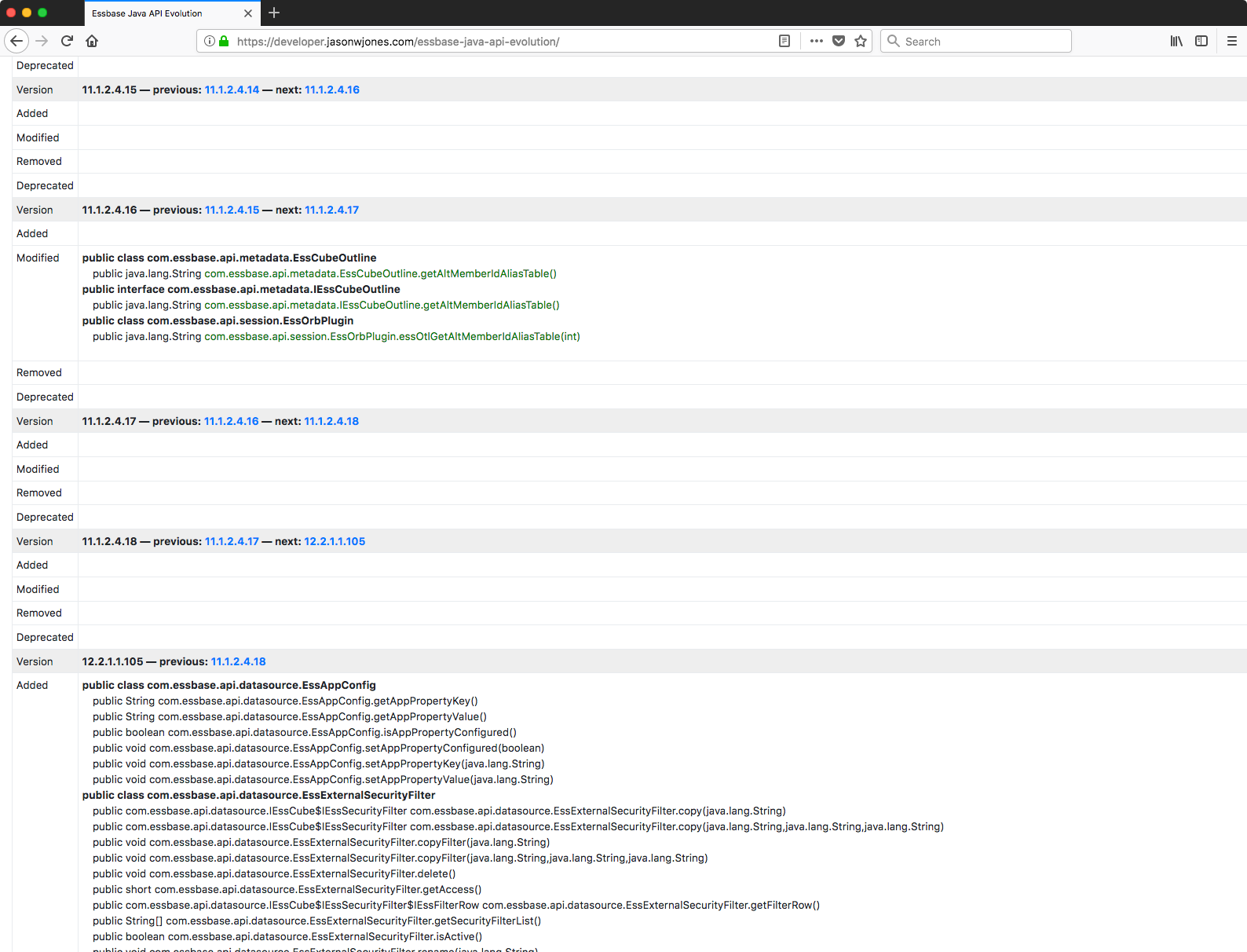
Screenshot from the Essbase Java API evolution analyzer
Improving MySQL JNDI Connection Reliability
I blogged quite some time ago about using JNDI to configure database connections in Dodeca. As I mentioned then, JNDI can bring some useful improvements to your configuration, management, security, and administration of your environment versus how you might be configuring normal JDBC connections. To be clear, this isn’t because JNDI connections are inherently better from a performance standpoint, it’s just that it might be a cleaner solution in various ways.
My original blog post looked at configuring a pretty typical MySQL connection in JNDI. As I have worked with this in the last few months, I have run into a few issues with the configuration as it related to connection timeout issues. I was occasionally getting some timeout issues like this:
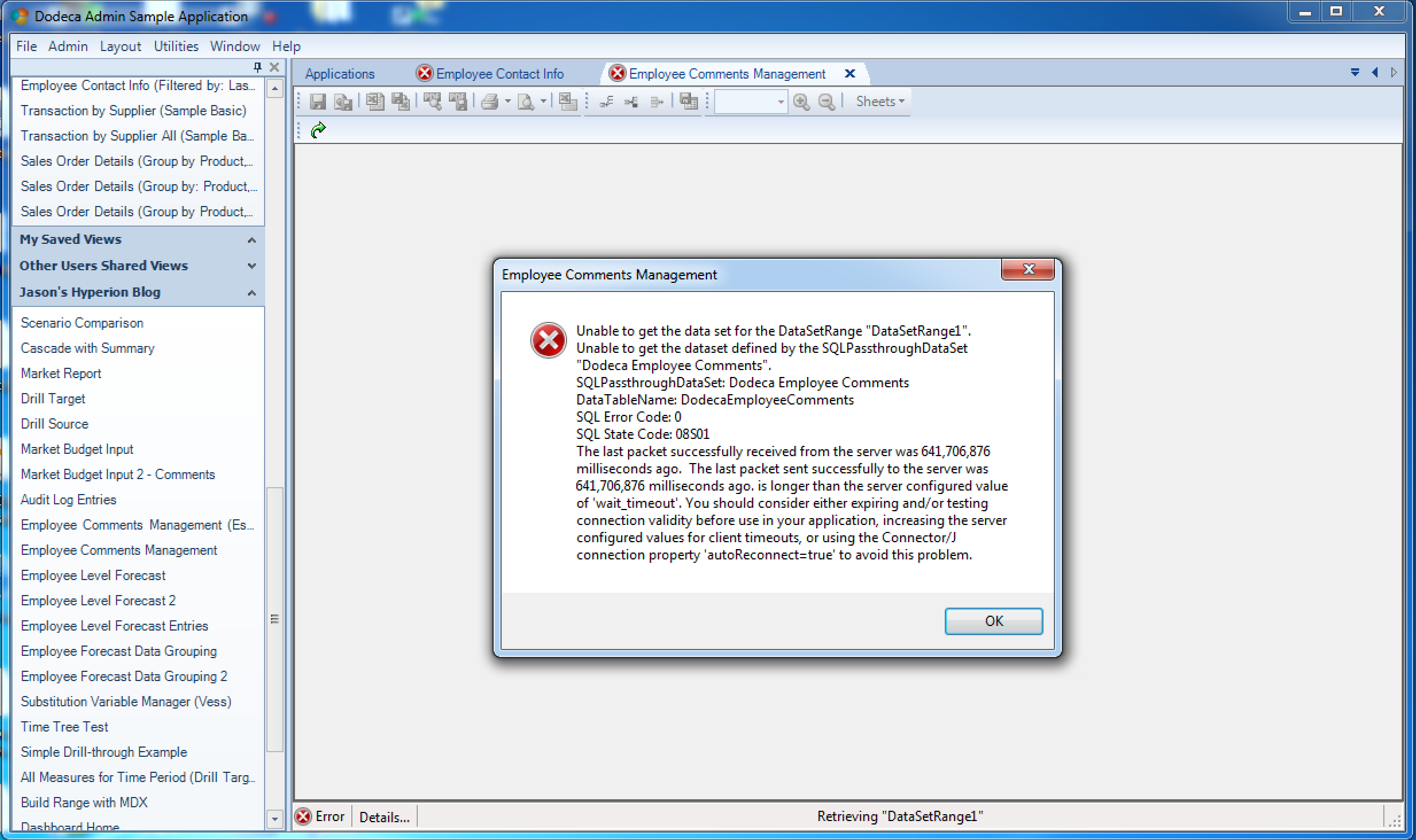
MySQL connection timeout when configured with JNDI
Helpfully enough (or perhaps unhelpfully) the error message itself reports that perhaps the autoReconnect=true setting would be of help. I’ve actually used that setting in the past and it seemed to help things out. But as it turns out, that setting is deprecated and should not be used. There are some alternative techniques that can/should be used to ensure the program gets a valid connection back.
One common technique is to specify a “validation query”. This is often something like SELECT 1 or SELECT 1 FROM DUAL depending on the particular database technology being used. You can use SELECT 1 for MySQL. What this essentially means is that before returning a connection via JNDI to the Java servlet to do things with, the connection pool manager is going to run the validation query to ensure that it is indeed a valid connection (able to connect, doesn’t error out, and so on.
Interestingly enough, MySQL in particular has added an optimization for this use case such that you can give it a sort of fake query (code: /* ping */) and it’s slightly more optimized than the overhead involved with a SELECT 1.
Together with this optimized test query, some additional attributes on the JNDI configuration (testWhileIdle, testOnBorrow, testOnReturn, and removedAbandoned, I’ve updated the overall JNDI configuration and it seems to be much more robust. Here’s the new connection JNDI code from my Tomcat context.xml:
<Resource name="jdbc/dodeca_sample" auth="Container" type="javax.sql.DataSource" username="dodeca" password="password" driverClassName="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost/dodeca_sample?noDatetimeStringSync=true" maxActive="100" maxIdle="30" maxWait="10000" removeAbandoned="true" removeAbandonedTimeout="20" logAbandoned="true" validationQuery="/* ping */" testWhileIdle="true" testOnBorrow="true" testOnReturn="false" /> <ResourceLink name="jdbc/dodeca_sample" global="jdbc/dodeca_sample" type="javax.sql.DataSource"/>
Essterm: Terminal-based ad hoc client for Essbase
Remember the last time you thought, “You know, Excel is just a little too modern, I wish I could do multi-dimensional analysis using my keyboard, in a terminal, the way the Pilgrims did it.”
Me neither.
Yet, here we are.
I was going to originally throw this over the fence release this as a bit of an April Fool’s joke, but I didn’t have quite enough time. I actually showed this off to the fine folks at my Collaborate session last month, and believe it or not, some of the people there thought it had some interesting use-cases. Continue Reading…
PBJ 1.0.4 – New password options and start of CLI
The PBJ library has been getting a lot of attention lately from various developers using it to integrate with their own software and projects. Francisco Amores did a great blog post about using PBJ to help with data loading in an FDMEE project. Probably the coolest thing about his efforts is that it’s use-case I never imagined: using PBJ in Jython to access PBCS.
One of the things that has been so great about collaborating with Francisco is getting targeted, useful, and practical comments on how he’s using the library and how it can be made better. And I have found time to make various improvements, enhancements, and fix bugs to address his feedback. This is one of the greatest things about open source software.
JDBC and JNDI connections compared (with a Dodeca example)
Have you ever wondered what the difference between a JDBC and a JNDI connection is? If you’re familiar with at least one of these, it’s likely that you’re familiar with JDBC (but probably not JNDI).
JDBC connections come up often in the Oracle world (for good reason). It’s a standard model/framework for designing drivers that interact with relational databases. As it pertains to us in the Hyperion, Dodeca (and even Drillbridge!) world is that we often define connections in terms of specifying JDBC parameters. This typically means a driver class name (like com.mysql.jdbc.Driver for a MySQL driver), a JDBC URL (a URL specifying a server and optionally a database/schema and other parameters), and credentials (username/password). So if you’ve poked around in your infrastructure much at all, there’s a good chance that you’ve come across a JDBC connection.
You may have even come across something called JNDI and even vaguely known it was sort of an alternate way to configure a connection but never really had to bother with it. I’ll spare you the acronym details, but think of JNDI as a way of organizing database connections (and other objects actually, but we don’t need to worry about that at the moment) such that instead of our app/system having to know the server name and credentials, it just asks “Hello, can I have the resource that was defined for me with name XYZ?”
Hacking the Essbase Java API to run Application Calcs
This post might alternately be titled, “So you’re really stubborn and wasted a couple of hours messing with the Essbase Java API”, or something. I was in a discussion the other day and asked about the ability to run an application-level calc script.
Well, back up, actually. Did you know that calc scripts can exist at the application level in Essbase? For a very long time, Essbase has had this notion of applications and databases (with databases often just being called cubes), such that there is usually one database/cube inside of an application, but there can technically be more (at least in the case of BSO). It’s almost always the best practice to have just one cube to an application. This is largely for technical reasons.
Hyperion Parent Inferrer Updated (after four years!)
I had a need for the Hyperion Parent Inferrer functionality for an internal project I am working on. It didn’t quite do what I needed out of the box so I updated things a bit. As quick background, the Hyperion Parent Inferrer is a simple one-off Java program/library I developed (apparently four years ago, wow) to parse indented data into an explicit parent/child file.
There are a few (apparently rare) cases where this is useful. In my case, I was modeling some hierarchical data and I find the indented format to be much easier on the eyes. Like so:
Time Q1 January February March Q2 April May June Q3 July August September Q4 October November December
But when it comes time to load in to Essbase, clearly we need something more explicit. The Hyperion Parent Inferrer takes that preceding as input and then outputs something like the following:
,Time Time,Q1 Q1,January Q1,February Q1,March Time,Q2 Q2,April Q2,May Q2,June Time,Q3 Q3,July Q3,August Q3,September Time,Q4 Q4,October Q4,November Q4,December
The program has been enhanced to allow for a custom indentation character (such as tabs), to be able to specify the text rendered when there is no parent (instead of null), and a couple other little cleanups.
Hyperion Parent Inferrer is free, open source (Apache Software License version 2), and can be run as a standalone command-line Java program or as a Java library that can be incorporated into a typical Java program. The updated code is available at the Hyperion Parent Inferrer GitHub page.