This week’s blog posts are all about the upcoming Kscope16 conference and relate to the presentations I’m part of. This year I am co-presenting with Cameron Lackpour on on-premise Planning versus PBCS and talking about some different use cases. My particular focus for this presentation is how you might use the PBCS REST API with Java.
Over the last year I have put together a Java library that works with the PBCS REST API. It has the following characteristics:
- Open Source (Apache Software License version 2.0)
- Doesn’t depend on any Oracle libraries or code
- High-quality, readable, fluent API
In my opinion, all of these goals have been met. Additionally, as of today, PBJ (PBCS Java Client) is available in Maven Central. What this means is that if you or your team programs in Java and use Maven for dependency management, you are just a few clicks away from being able to use this library.
For an overview of why you might want to use PBJ and how it compares to other scripting languages you might want to use instead (such as Groovy, Python, and more), come check out the presentation!
Today, however, I want to show how easy it is to incorporate PBJ into a Java program and do something quasi-practical. So the rest of this article will be oriented towards programmers, but for those of you that have employees or teammates that would be more likely to do the programming aspects of things, keep them in mind and send them a link.
First, let’s assume we’ve already created a new empty Maven project in Eclipse. Your experience will vary if you use IntelliJ IDEA or some other IDE. In this example I happen to be using Springsource Tool Suite (STS), which is pretty much the same as Eclipse.
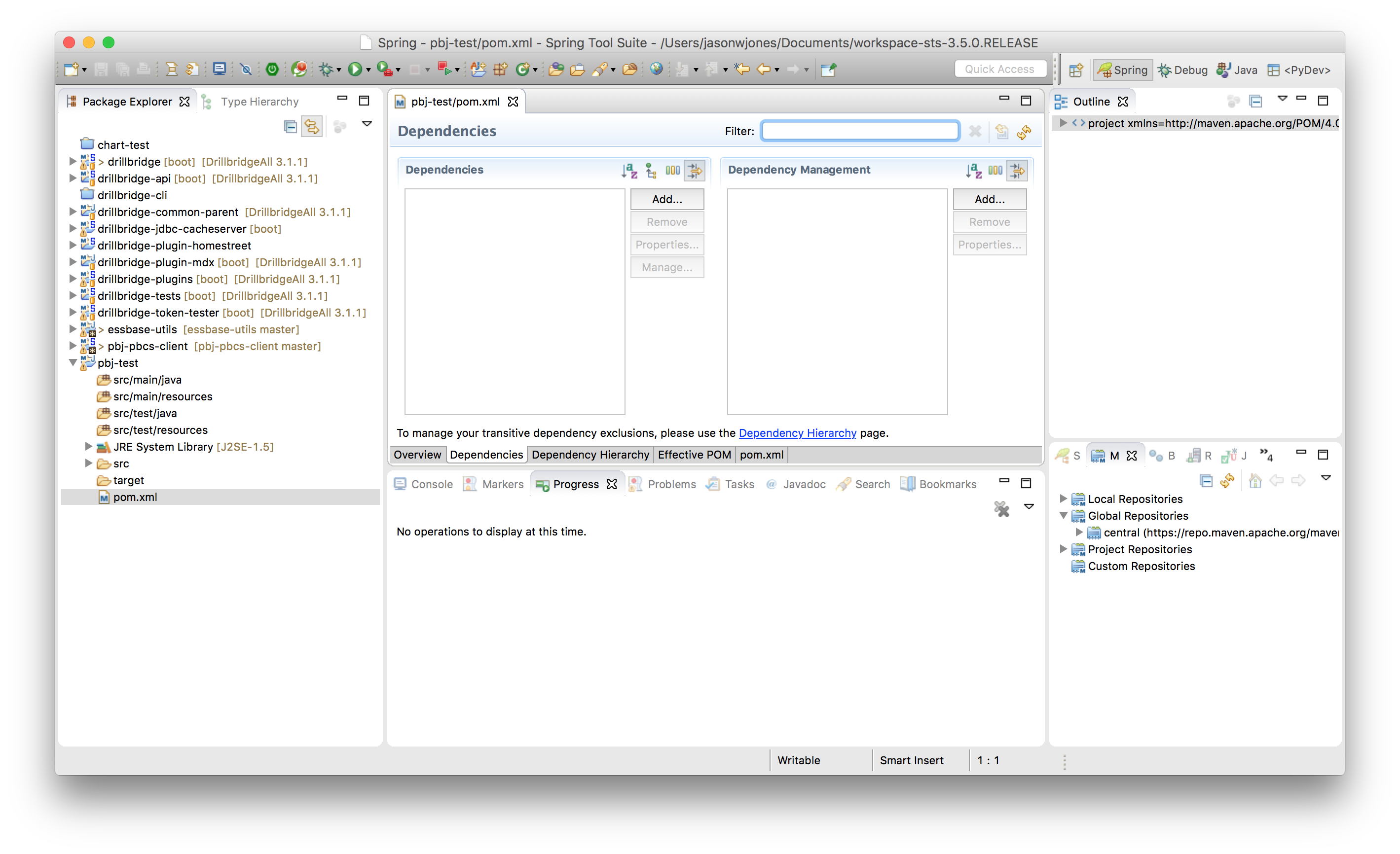
Next we need to open up our pom.xml (project definition file) to add a new dependency. You can do this manually by editing the XML file itself, but there’s a nice enough GUI in Eclipse that makes things even easier:
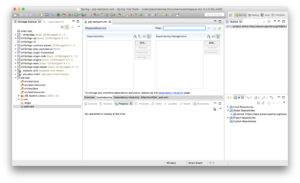
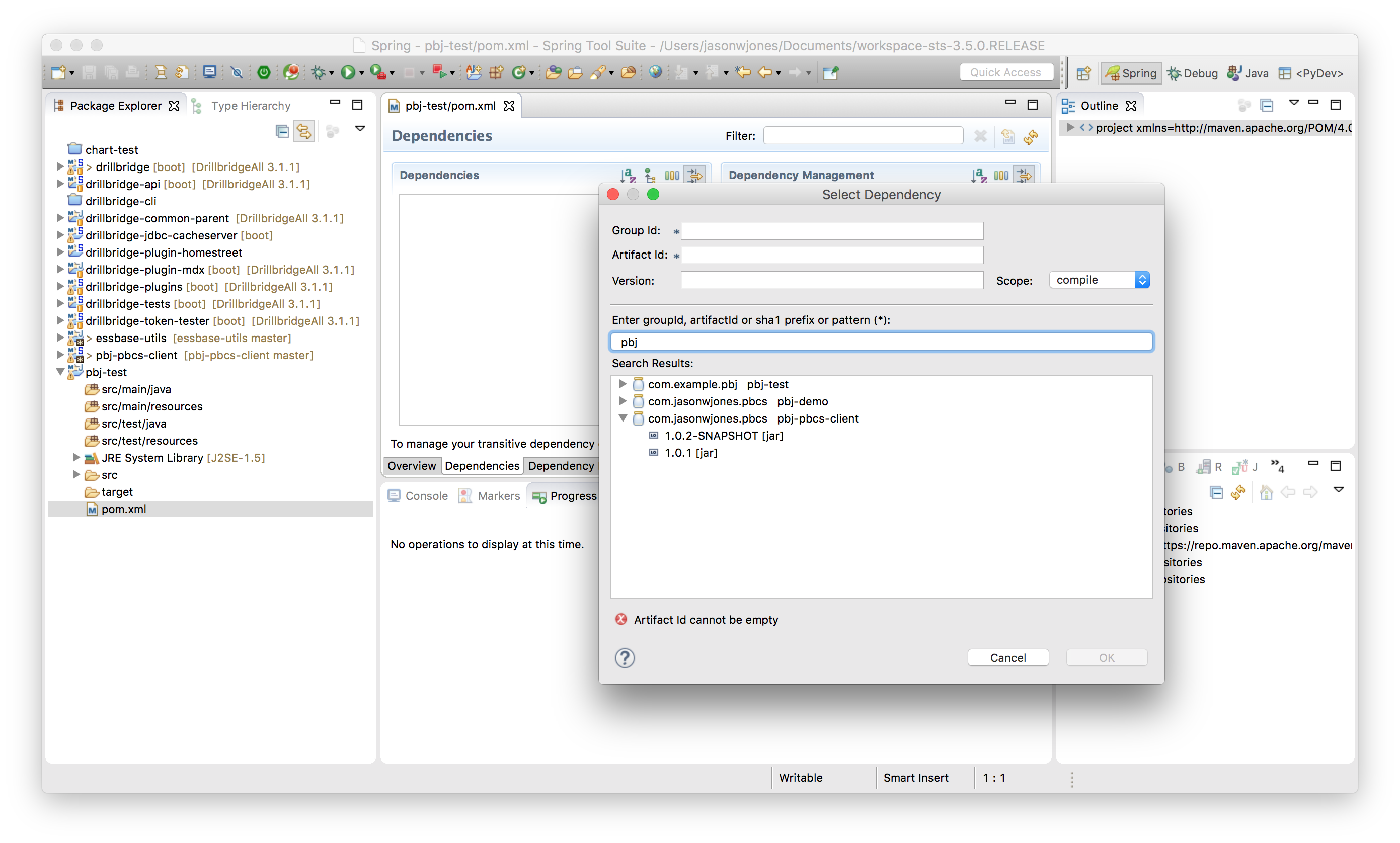
Next we need to go find the PBJ library. As I mentioned earlier, PBJ is available in the global Maven Central repository. If you have Maven set to update its index periodically or upon startup of your IDE, then you should be up to date and can find the PBJ library. As of right now the version of PBJ is just 1.0.1.
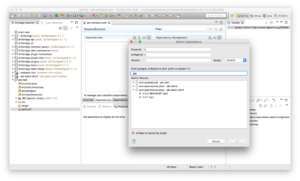
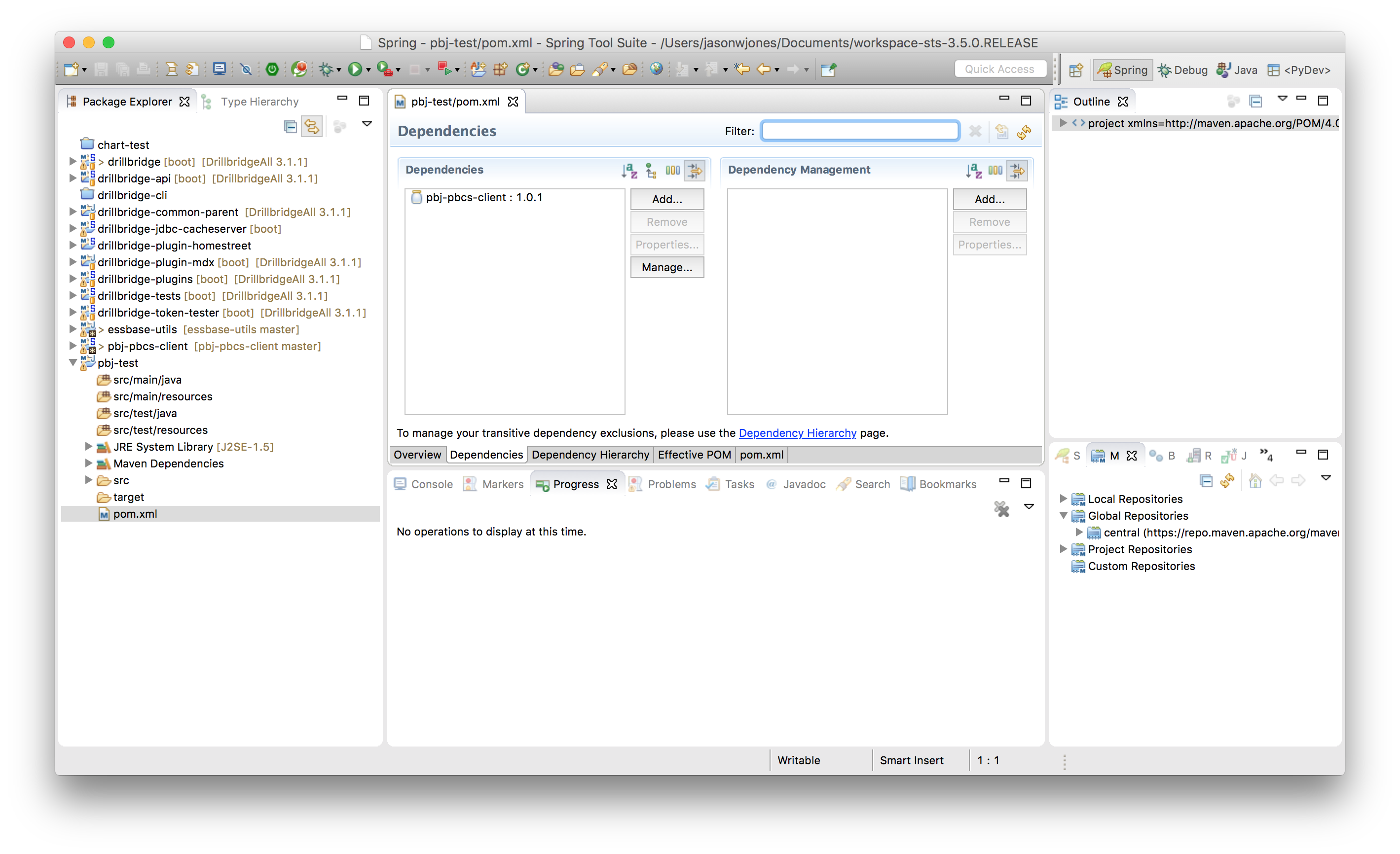
Select the library, click OK, and then save the file. The PBJ library and its dependencies are added to your project.
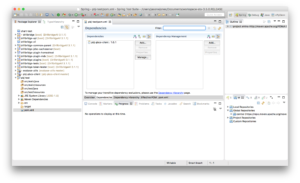
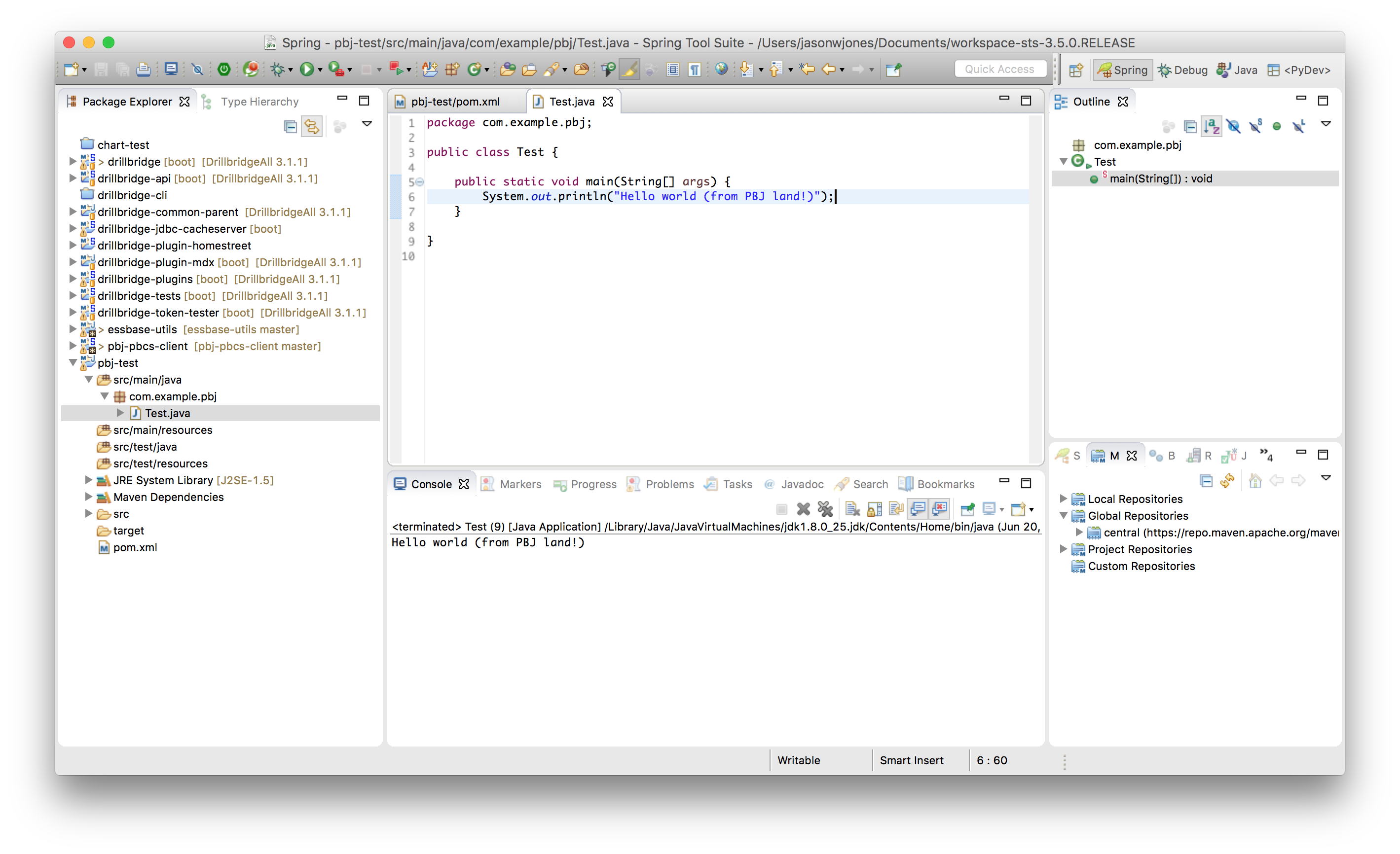
Now we can create a new main class to test things out. At this point it’s just life as normal for the Java developer:
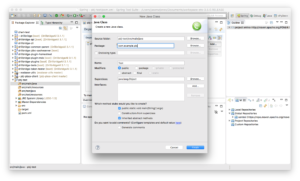
Just for good measure (and tradition!) let’s put in a simple code to print out “Hello world”, and run it. Note the output in the bottom middle pane:
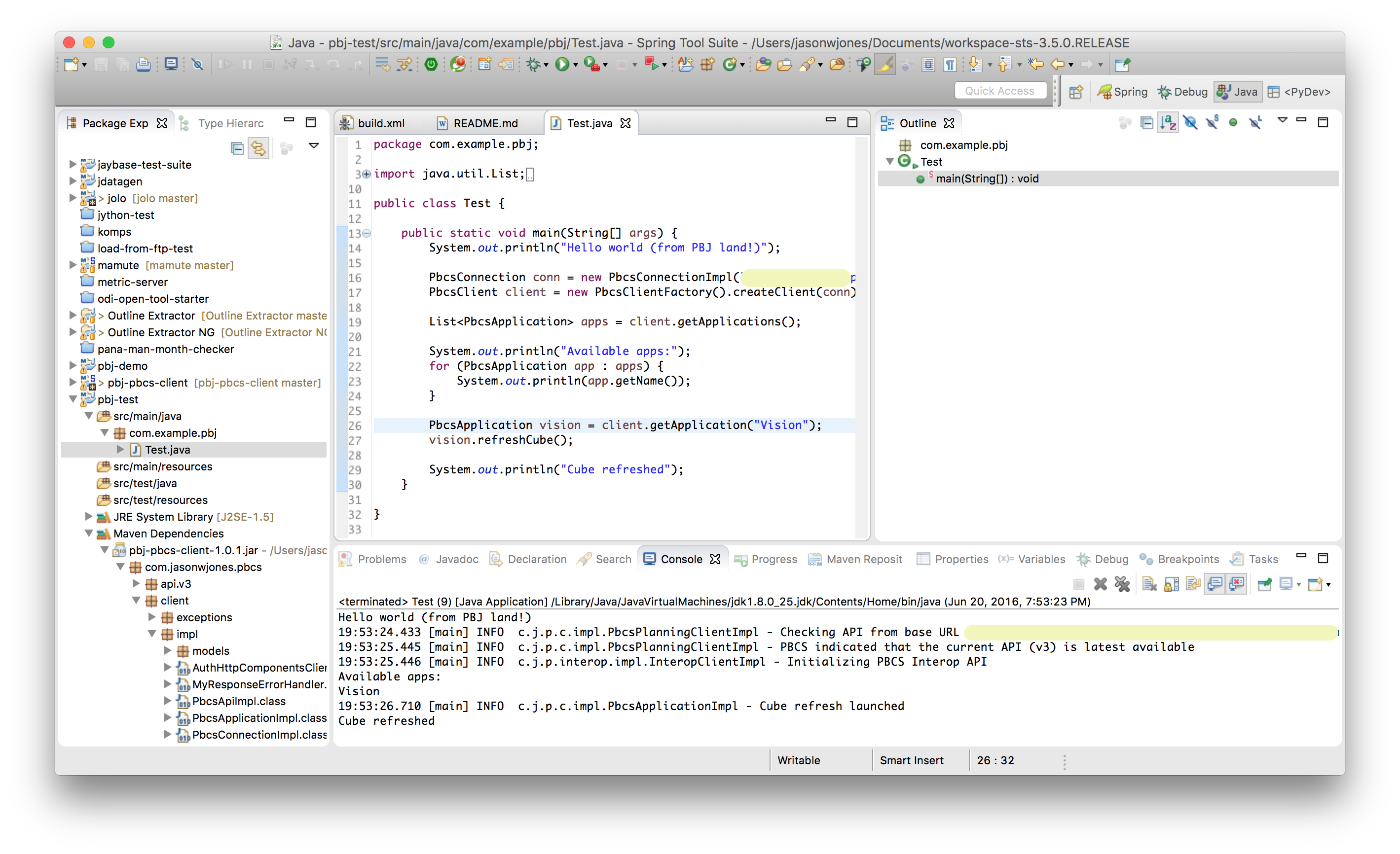
At this point we have project setup, we have all of the necessary PBJ files (and some additional transitive dependencies), and we are ready to write some Java code that uses methods in the PBJ library. The code to write is shown below:
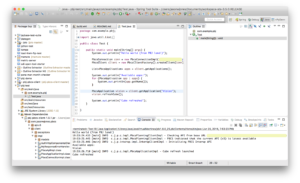
In the code you can see the following happen:
- A connection details object is created
- A connection to PBCS is made
- Ask for the list of available apps
- Print out the list of available apps
- Get a reference to a particular app (“Vision”)
- Call the refreshCube method on the app reference to refresh the cube
- Print message after cube refresh
It’s hard to imagine this code being much simpler. If might look like greek if you’re not familiar with programming or Java, but to a Java programmer, this will be readily comprehensible and its intent obvious. PBJ supports most of the REST API – importing data, metadata, business rules, and more.
To see a specific use-case and hear wry commentary from myself and Cameron, please swing by our presentation. We’ll cover an example of PBJ (don’t worry, it’s higher level than this!) but more generally some facets of administration of on-prem versus PBCS will be discussed as well. I think the presentation will really appeal to many different user groups.