While not as good as the webinar with audio (are you an ODTUG member that can watch it?), here is the Drillbridge Webinar Slides for the webinar for those that are interested! Thanks again to ODTUG for all they do for the community and hosting this presentation.
Monthly Archives: October 2014
Drillbridge with Teradata & Netezza?
The ODTUG webinar for Drillbridge yesterday seemed to go pretty well (more to come soon!) but one of the questions that came up is if Drillbridge works with Teradata and/or Netezza for implementing Hyperion drill-through to relational. My answer: it should, but I don’t know for sure. Drillbridge supports Microsoft SQL Server, Oracle, and MySQL out of the box. Drillbridge also allows you to put your own JDBC driver into it’s /lib folder and you should be able to use any other flavor of database that you can write SQL for: be it Informix, DB2, Teradata, Netezza, or whatever.
So that being said, if you are interested in implementing Drillbridge and using one of these backend relational databases, please don’t hesitate to reach out to me if I can help with it. I’d love to be able to confirm compatibility rather than to just say “I suspect it will work, JDBC is awesome, right?”
How to scan a cube for members with no data – the HUMA way
I recently dusted off one of my Hyperion/Java flights of fancy the other week: HUMA. HUMA is a tool for scanning a cube and finding which members have no data associated with them at all. As I mentioned in the post talking about some performance tweaks, HUMA scans every single cell in an entire cube to determine what is empty.
One of the reasons I put HUMA on the self for a while is that in a program that does this, there’s a lot that can go wrong to cause the program to fail or run so long that the sun goes supernova before the program finishes. If you were lucky then you’d get a list of members that you could put on the chopping block. If you’re lucky it’s even a member in a dense dimension, whose removal might just increase your block density ever so slightly.
That all being said, let me just say up front that maybe there’s not a lot to be gained from doing this. Maybe the real solution is to buy some nice fast SSDs for your server, or increase the cache size, or check out that fancy new ASO Planning stuff, or whatever. Let me just say upfront that I get that. Nevertheless, this tool exists and if you’re the type of administrator who looks for any edge you can get, well, then maybe you’re one of the dozens of masochists people that have already downloaded this thing.
So, for the curious: how do you and how does HUMA scan an entire cube with a kajillion possible data cells? Glad you asked…
Step 1 – Read the outline
The first thing that HUMA does is read the outline for the list of stored members in each dimension. HUMA also pays attention to which dimensions are sparse and which are dense.
Step 2 – Build a virtual grid with every single cell combination
Imagine you’re in Smart View and you are drilling around Sample/Basic. You drill to the bottom of each dimension, and now there is nothing in your POV – it’s just rows and columns as far as the eye can see. You’d have something like this:
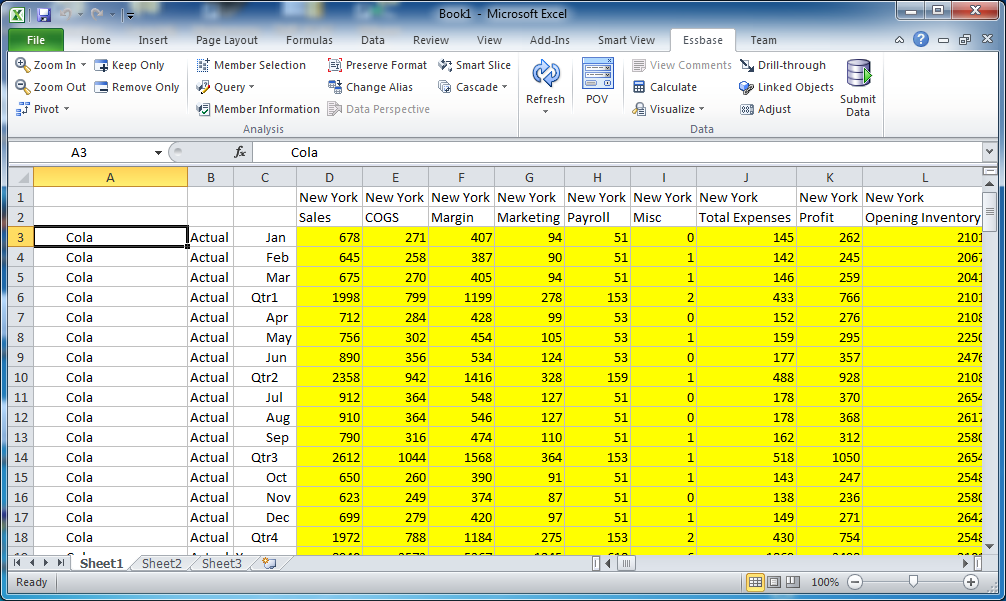
All dimensions in the Sample.Basic database have been drilled into; there are no POV/page members.
In practice, even a barely non-trivial combination of members from multiple dimensions results in a grid that is gigantic – and too big to store in memory all at once. HUMA doesn’t actually generate this grid in memory, thankfully. It generates (incredibly quickly) the member combinations for any place in the grid. Hence why it’s a virtual grid. From here the problem is actually kind of simple sounding: just check all the cells. Before we do that, let’s come back to why we paid attention to dense and sparse:
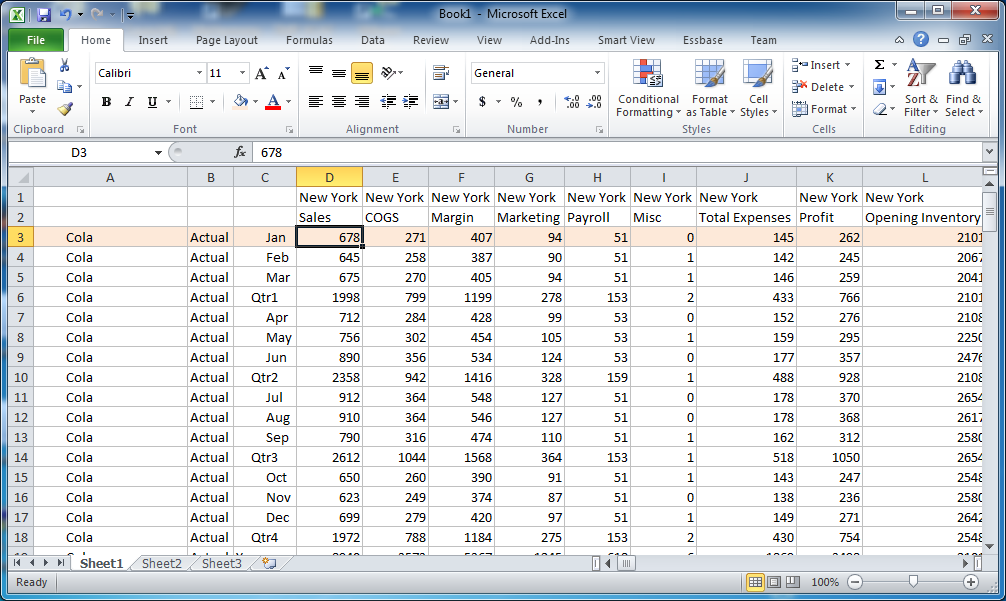
A single row is highlighted: given columns A-C representing sparse dimensions, then the highlighted row represents the entirety of a single block.
Spare dimensions are on the left, dense dimensions are on the top. So you can see that the highlighted row in the above screenshot corresponds to a data block (in a BSO database). The data is strategically laid out this way so that to the extent possible we will be retrieving data against the same blocks over and over, giving the Essbase engine a chance to leave those in memory and serve them up faster.
Step 3 – Retrieve sub-grids
We can’t, obviously, just pull back all the data at once… we need to iterate through it. For technically reasons we also need to limit the number of cells we pull back at once, and we have a maximum number of columns (for Java API purposes) of 256. We might want to set the max cells per retrieve though. So let’s say that’s about 50 cells. We’d then be retrieving sub-grids roughly shaped like this:
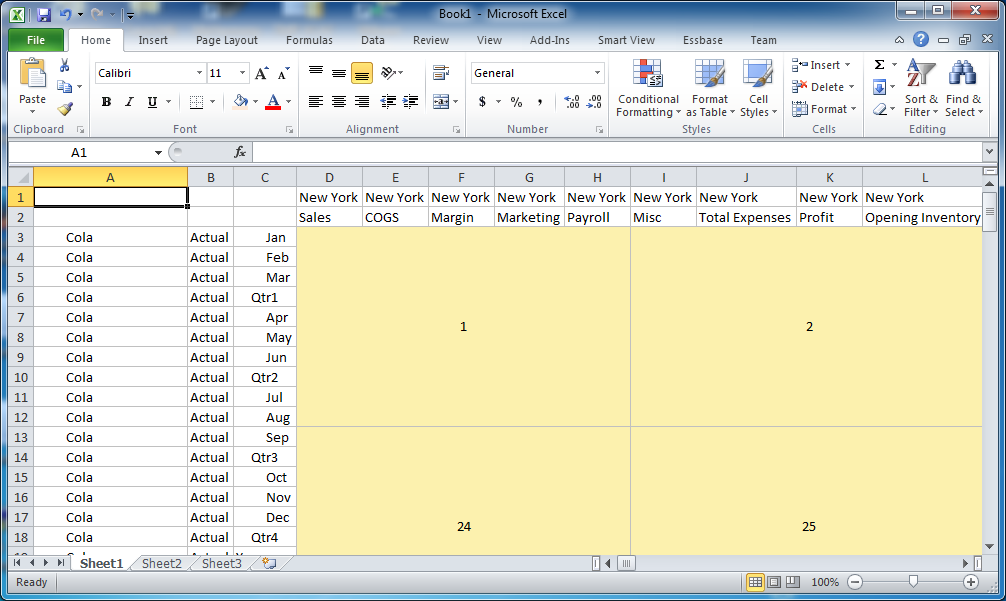
A fully expanded grid with different sub-grids of data represented. The top left starts out as grid 1, then moves right to grid 2 and keeps moving right. The next row picks up at theoretical sub-grid number 24.
See that the first grid is one, then to the right (in the same “hot” blocks) is 2, and then so on through to the right side such that the next grid down in this case happens to be 24, then 25, and so on. Even if we just retrieved (or tried to retrieve) all of these grids, it would still take a considerable amount of time. So there’s one more trick up HUMA’s sleeves: quick member elimination. Let’s look at the data in grid 1:
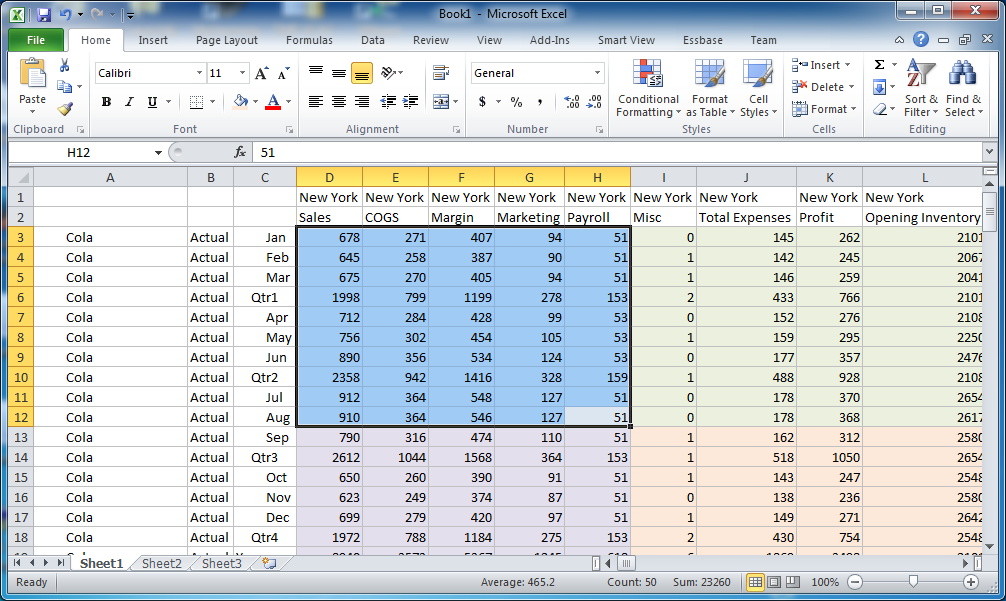
Another look at the data contained in HUMA sub-grid number 1.
Step 4 – Analyze data and reconfigure search space
We’ve found data for such member combinations as Cola, Actual, New York, and so on. We can now remove these from consideration in the search. HUMA knows that it no longer has to ever check any of those members. Because of it’s extremely fast grid regeneration/iteration, it does this automatically and shrinks the search space by removing those members. This can speed things up incredibly. If you watch the [at the moment very verbose] HUMA output, you’ll see some debugging information about how many grids there are, and as members are found, this number gets recomputed.
HUMA will finish in one of two ways: it eliminates every member from consideration for being unused and it quits, indicating as much, or two, it finishes and it reports back all of the unused members. I guess there’s a third option, which is that HUMA crashes. Actually, HUMA itself won’t crash, but the most likely issue you’ll run into is port exhaustion, in which case you’ll want to increase the milliseconds between retrieves and try again (or just increase the number of ports on the server, as indicated in the help).
That, in a nutshell, is how HUMA operates. This time around, performance is off the charts compared to what the first version was, so that’s cool. This program is available from the Downloads site. This is still a very rough program but please feel free to share your feedback and experiences.
Daily Drillbridge Update
Lots of exciting things going on in the Drillbridge world! I am putting the finishing touches on my ODTUG webinar that is NEXT WEEK (the 28th!). You can register here or wait for the recording to be released. I’ll put a link on this blog.
The “context path” update in the Drillbridge 1.3.4 beta appears to be working swimmingly – enabling the use of a proxy with Oracle HTTP Server so that Drillbridge can be used on a normal web port and URL of your own choosing, so that’s super cool.
Source Code Metrics
Just for fun, I ran the Drillbridge codebase through a source code analyzer and it is just shy of 5,000 lines of Java, not counting over 1,000 lines of comments. Pretty cool stuff! Believe it or not, Drillbridge started out as a proof of concept with about 3 Java class files (now it’s weighing in with 120 classes).
Drillbridge 1.3.4 BETA available
The normal Downloads location now contains a beta of Drillbridge 1.3.4. This release only adds one requested feature: custom context paths. Normally, Drillbridge operates at the root of its web container, such as http://server:9220/admin/reports. This change adds support for putting in an application.properties variable that allows for a custom context path. So instead of the above link, you’d use http://server:9220/drillbridge/admin/reports. Note that the name of the root (in this case drillbridge) can be set to whatever.
If you use this feature you’ll have to edit your drill-through definition (the code that goes into EAS or gets deployed from Drillbridge) by hand, although you were probably doing that anyway if you needed this feature. This feature is simply meant to allow for putting IIS in front of Drillbridge in case you want to do a redirect and offer Drillbridge through your normal web server on port 80.
If you don’t need or want to test this feature, just stick with 1.3.3. The downloads section now clearly indicates that this is a beta.
Thoughts on using an ODI SKM to expose tables as a web service
It seems that I am trucking right along in my quest to every nook and cranny of what Oracle Data Integrator has to offer (in the words of imitable Cameron Lackpour, “Wait, you use ODI for real ETL stuff?”). People always talk about ODI’s knowledge modules (KMs) and are typically referring to the workhorse RKM, LKM, and IKMs. A more exotic and less talked about KM is the SKM – Service Knowledge Module.
The idea behind an SKM is fairly straightforward. One of the fundamental building blocks in ODI is the data store – this is typically, but not always, a table in a a relational database. We end up spending a good bit of our lives figuring out how to make data go from many source data stores to a target data store.
What’s this SKM business all about? It builds a web service with typical “CRUD” operations that you can deploy. This means we end up with a web service that clients could use to add, get, and search data in data stores we have.
There are several usage scenarios for this that I can think of. One, it might be a lot more tenable to deploy web services to expose data than to expose the database itself (think network security and such). That’s probably a slam dunk use case on its own right there. Second, you might want to access data from a language that doesn’t have support for your underlying data source technology. Third, it could just be a good architectural abstraction – making your clients oblivious to the exact underlying data source, giving you the flexibility to swap it out without affecting clients.
For the sake of argument, let’s say we have a dozen tables in a MySQL database and we’d like to expose a few of them as a web service. ODI Studio let’s us pick which data stores, and the SKM. Then we just define a JAX-WS server and deploy them.
In my case, I decided to deploy to a Wildfly server (aka JBoss AS). This is a JavaEE application server. It’s like WebLogic – but not like Tomcat – Tomcat is technically just a servlet container and it doesn’t contain all of the functionality that the ODI web services need (the EE part of JavaEE). In fact, I originally tried to deploy to Axis2 running under Tomcat 7 only to discover that Axis2 support has been deprecated/removed (for those not familiar, Axis2 is a project that runs in a servlet container that provides a base for exposing web services). So first note, do not use Axis2, especially if you are playing around in ODI 11, because I can’t even get it to work in ODI 12.
Other than that, ODI dutifully generates a bread and butter WAR file that can be deployed to JBoss (again, the typical deploy server is probably WebLogic but I’m a bit of a Red Hat guy so…). The ODI generated web service expects a JNDI data source to be configured. Again, for those of you not familiar, all JNDI does is makes it so that the WAR (servlet/application/web service) doesn’t need to include it’s own particular database connection details. So rather than a particular web service being hardcoded to a certain database server and using a particular username/password, it allows the application to say “Hey there mister application container, can you give me the ‘Finance’ database connection? Thanks!” and goes on its merry business. I ran into a small snag with the JNDI configuration that required me to modify the web.xml code to add in a <lookup-name> tag for my JNDI data source but other than that, the service deployed without a hitch.
So now on to the service itself: you get a traditional SOAP-based web service complete with WSDL file for consumption by clients. For easy testing you can point an application like SoapUI to the WSDL file and generate methods that you can easily test with. You can methods to add and list and filter. You can specify as much or as little data to filter on for a given entity (data store) so long as you include the primary key. Any data store in the web service exposed by the SKM must have a primary key, that’s the main catch – not that it should be to burdensome, since if you aren’t designing tables with primary keys, you might have bigger problems when it comes to using ODI…
Thoughts so far:
- Don’t use Axis2 to deploy SKMs (doesn’t work/not supported anymore)
- Wildfly (JBoss AS) does work, but seems to need a web.xml tweak for JNDI
- You might not have a JavaEE (Wildfly, WebLogic) container setup already, this could be a hurdle
- Generating the web service is pretty slick
- You get an “old school” WSDL-based web service
I actually really like how slick this can be. If you already have an application server and a set of data stores you want to expose, then boom, you can be up and running with a web service to provide access to those pretty easily. I guess the bigger question is this: is this what you want to do? Many web services are much more semantic in nature – i.e., your clients or potential clients might want more cohesive data rather than having to reach out to this table, that table, and some other thing, then combine it together into something. You wouldn’t use this, among other reasons, to expose Twitter data, for example.
As an additional thought, these SKMs have been around for quite some time – ages in the internet world. As a fairly experienced Spring developer, there have been amazing advances in things such as the Spring Data, Spring Data REST, and other technologies that allow one to build web-based create/read/update/delete operations on simple domain objects, and do it with a more modern technology stack such as to provide JSON payloads and use HTTP verbs such as POST/PUT/DELETE and so on. So personally I’d be more inclined to go in that direction to expose data than the SKM route.
But at the end of the day, if you have a set of tables you just need to expose over the web for whatever reason, this is a nice, low-investment way to accomplish that.
HUMA 0.5.0 available to download
An early build of the Hyperion Unused Member Analyzer is now available to download.
I posted details over in the Saxifrage Systems LLC “tools” forum with some brief notes on how to run and use the tool. Again, just to iterate (and so I have a clear conscience), it’s super alpha software, so there’s no warranty on this thing. Do please let me know your feedback either in email or the forum post. Future iterations of the software will clean it up.
HUMA Lives: A tool for determining if members in a cube have no data
So, just whatever happened to HUMA – the Hyperion Unused Member Analyzer? Well, a few things. One, Drillbridge happened which was a little proof of concept that somehow morphed into a real life tool (now in production in multiple environments and continents… you’re next, South America!) over the course of six months.
Two, it was – and is – a quirky little tool. Put shortly, there’s a lot that can go wrong when running HUMA but not a whole lot that can go right. There’s Essbase version issues, port exhaustion issues, performance issues, and all sorts of things that can pop up.
The main issue is the performance. There’s no magic trick to how HUMA works – it literally reads the entire outline for stored members, generates every single unique combination of members (the Cartesian product), and goes about retrieving them. Every. Single. One.
Ever look at the stats for a cube and go to the tab where EAS tells you the total possible number of cells? If you haven’t, it’s not hard to find. In fact, you can even squint when you look at that tab in EAS. Basically you’ll see a bunch of really reasonable numbers on the page, and then you’ll see a number that’s just incredibly, seemingly out-of-place huge. In fact, the colorblind masochists fine folks that designed EAS should have programmed EAS such that instead of showing the number, it should just say “seriously, it’s huge, why bother?”
Anyway, even for non-trivial amounts of members in a cube I determined that HUMA would almost literally take until the end of time to run. So HUMA needed to get smart in order to try and finish analyzing a cube before the the sun goes supernova.
To that end, I have made a couple of big changes to improve the performance of HUMA. I’m going to geek out here for a minute. You don’t need to read the next few paragraphs in order to use HUMA, and if I come across as a pretentious geek that’s showing off, well… I probably am. I’m proud of this junk.
Grid Generation Speedups
The first big change is to rework how the grids that HUMA retrieves are generated. As I mentioned, HUMA reads in the stored members from dimensions and uses the different combinations of members to generate all the possible data cells in a cube. Funny thing is, even when I took out the Essbase grid retrieve, the thing still took quite awhile to run. It turns out that generating these member combinations across a whole cube is computationally intensive. So I adapted one of my workhorse Java libraries to iterate through all the combinations really fast, so I could keep them from clogging up memory. The result is amazing – grid generation just flies now. This library is called Jacombi (Jason’s Combinatorics Library) and is now robust and battle-tested, being used in Drillbridge, Saxbi, HUMA, and cube-data (a tool that generates test data for cubes). So with the member combination generation problem solved, it was time to turn on grid retrievals and optimize more.
Quick Member Elimination
The next big, and probably even bigger win than the above in terms of performance is quick member elimination. Earlier versions of HUMA would count up the occurrences of data in the cube. In the new version, once data has been detected for a given member, it’s quickly removed from the search space. For example, if HUMA retrieves a grid for scenarios Actual and Budget, then determines that there is data for Actual, it will skip it in all future grid pulls. This can dramatically reduce the search space. In fact, it can hack away at the search space amazingly quickly. The ability to recompute the analysis space is directly enabled by the previous optimization. For non-trivial datasets, the grid generation step was long. Now it’s instantaneous. Effectively HUMA starts to zero in exactly on where there isn’t data. The more data you have in the cube, the quicker it eliminates potential unused members and finishes.
I just ran HUMA on Sample Basic with stock data and it scans the entire cube in a few seconds. I’m not saying this is the performance you can expect with your cube but it’s promising.
Testers?
This new version of HUMA is incredibly alpha quality – not even beta. Right now it’s still a console app and the log file is incredibly messy. A few of you over the last year have expressed quite an interest in helping out, so if you want to do some testing (or testing again), please comment on this post or contact me. I have a build ready to go. In the next week as time permits I’ll put it on the download site where Drillbridge and others are, and eventually build up to a slightly more polished release. I think this tool would look great in a GUI but I don’t quite have the bandwidth right now to design one up, so a nice old-fashioned terminal is what it’s going to be for now.
Thanks!
Drillbridge 1.3.3 Update 2
Such is the case with software, but there were a few other issues pointed out to me, this time with Excel file generation. So, the good news is that I fixed it (I think) and actually fixed another small issue that I noticed could pop up (and edge case with certain types of reports).
Excel files will now be generated in streaming mode, as with the much enhanced report generation, so that’s cool. Also, unlike before, the Excel file generation will now honor the Smart Formatting option if you have that turned on, so that’s even more awesome.
One bad thing I just discovered, though, that I hadn’t though of, is a quirk with trying to download Excel files from Drillbridge pages that are paged. This is a bit problematic due to how to write the query, so for the time being I must say: no Excel file download on reports with Enable Paging turned on. I have tweaked the HTML so this option won’t even show.
Paging turns out to be a somewhat problematic issue due to the complexities of supporting multiple database backends, performance, and other things. So for now it’s just considered experimental.
A new Drillbridge 1.3.3 package has been uploaded to the download site with the aforementioned fixes.
Thanks again to those of you providing feedback and living on the bleeding edge of this thing. Version 1.3.1 is still the gold standard for now but 1.3.3 is just about there, I think. In any case, things should settle down from here on out in terms of major code changes.
Happy Drilling.
Drillbridge 1.3.3 re-updated
There was a little issue in Drillbridge causing editing reports to not work. This was due to a column I introduced whose SQL code to update the internal Drillbridge database was not set correctly, so the column didn’t get added. Then when you would go to edit a report, it would try to query a non-existing column, causing it to fail. I’ve since fixed this and re-uploaded Drillbridge 1.3.3. Please let me know if any other issues.