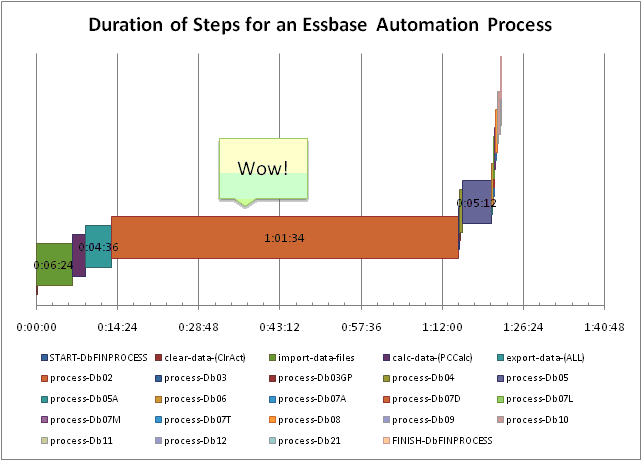
Did you know that you don’t have to run your MaxL automation on the Essbase server itself? Of course, there is nothing wrong with running your Essbase automation on the server: network delays are less of a concern, it’s one less server to worry about, and in many ways, it’s just simpler. But perhaps you have a bunch of functionality you want to leave on a Windows server and have it run against your shiny new AIX server, or you just want all of the automation on one machine. In either case, it’s not too difficult to setup, you just have to know what to look out for.
If you’re used to writing MaxL automation that runs on the server, there are a few things you need to look out for in order to make your automation more location-agnostic. It is possible to specify the locations of rules, reports, and data files all using either a server-context or a client-context. For example, your original automation may have referred to absolute file paths that are only valid if you are on the server. If the automation is running on a different machine then it’s likely that those paths are no longer valid. You can generally adjust the syntax to explicitly refer to files that are local versus files that are remote.
The following example is similar in content to an earlier example I showed dealing with converting an ESSCMD automation system to MaxL. This particular piece of automation will also run just as happily on a client or workstation or remote server (that has the MaxL interpreter, essmsh installed of course). Keeping in mind that if we do run this script on our workstation, however, the entries highlighted in red refer to paths/files on the server, and the text highlighted in green refer to things that are relevant to the client executing the script. So, here is the script:
/* conf includes SET commands for the user, password, server logpath, and errorpath */ msh "conf.msh"; /* Transfer.Data is a "dummy" application on the server that is useful to be able to address text files within a App dot Database context Note that I have included the ../../ prefix because with version 7.1.x of Essbase even though prefixing the file name with a directory separator is supposed to indicate that the path is an app/database path, I can't get it to work, but using ../../ seems to work (even on a Windows server) */ set DATAFOLDER = "../../Transfer/Data"; login $ESSUSER identified by $ESSPW on $ESSSERVER; /* different files for the spool and errors */ spool stdout on to "$LOGPATH/spool.stdout.PL.RefreshOutline.txt"; spool stderr on to "$LOGPATH/spool.stderr.PL.RefreshOutline.txt"; /* update P&L database Note that we are using 3 different files to update the dimensions all at once and that suppress verification is on the first two. This is roughly analogous to the old BEGININCBUILD-style commands from EssCmd */ import database PL.PL dimensions from server text data_file "$DATAFOLDER/DeptAccounts.txt" using server rules_file 'DeptAcct' suppress verification, from server text data_file "$DATAFOLDER/DeptAccountAliases.txt" using server rules_file 'DeptActA' suppress verification, from server text data_file "$DATAFOLDER/DeptAccountsShared.txt" using server rules_file 'DeptShar' preserve all data on error write to "$ERRORPATH/dim.PL.txt"; /* clean up */ spool off; logout; exit;
This is a script that updates dimensions on a fictitious “PL” app/cube. We are using simple dimension build load rules to update the dimensions. Following line by line, you can see the first thing we do is run the “conf.msh” file. This is merely a file with common configuration settings in it that are declared similarly to the following “set” line. Next, we set our own helper variable called DATAFOLDER. While not strictly necessary, I find that it makes the script more flexible and cleans things up visually. Note that although it appears we are using a file path (“../../Transfer/Data”) this actually refers to a location on the server, specifically, it is the app/Transfer/Data path in our Hyperion folder (where Transfer is the name of an application and Data is the name of a database in that application). This is a common trick we use in order to have both a file location as well as a way to refer to files in an Essbase app/db way.
Next, we login to the Essbase server. Again, this just refers to locations that are defined in the conf.msh file. We set our output locations for the spool command. Here is our first real difference when it comes to running the automation on the server versus running somewhere else. These locations are relevant to the system executing the automation — not the Essbase server.
Now on to the import command. Note that although we are using three different rules files and three different input files for those rules files, we can do all the work in one import command. Also note that the spacing and spanning of the command over multiple lines makes it easier for us humans to read — and the MaxL interpreter doesn’t really care one way or another. The first file we are loading in is DeptAccounts.txt, using the rules file DeptAcct.
In other words, here is the English translation of the command: “Having already logged in to Essbase server $ESSSERVER with the given credentials, update the dimensions in the database called PL (in the Application PL), using the rules file named DeptAcct (which is also located in the database PL), and use it to parse the data in DeptAccounts.txt file (which is located in the Transfer/Data folder. Also, suppress verification of the outline for the moment.”
The next two sections of the command do basically the same thing, however we omit the “suppress verification” on the last one so that now the server will validate all the changes for the outline. Lastly, we want to preserve all of the data currently in the cube, and send all rejected data (records that could not be used to update the dimensions) to the dim.PL.txt file (which is located on the machine executing this script, in the $ERRORPATH folder).
So, as you can see, it’s actually pretty simple to run automation on one system and have it take action on another. Also, some careful usage of MaxL variables, spacing, and comments can make a world of difference in keeping things readable. One of the things I really like about MaxL over ESSCMD is that you don’t need a magic decoder ring to understand what the script is trying to do — so help yourself and your colleagues out by putting that extra readability to good use.