I made a few adjustments and fixes to the experimental Thriller MDX over JDBC driver I have been playing with off and on. As a quick recap, Thriller is a normal JDBC driver that essentially passes MDX queries straight through to an Essbase server, and then maps the results into a normal JDBC ResultSet using a set of provided “hints” that tell it how to make George Spofford cry flatten the results.
There were a couple of issues related to how queries with various CrossJoins were handled that should now be fixed. Additionally, there are now a couple of new options to provide more configurability over how tuples are split or joined together. Things are definitely getting interesting for this concept.
As an example of a query you can run on Sample/Basic, check this out (thanks for Kyle Bourelle for doing the hard work of writing the query):
/**
*
* -- column.1.name = ENTITY
* -- column.1.type = VARCHAR
* -- column.2.name = ACCOUNT
* -- column.2.type = VARCHAR
* -- column.3.name = PERIOD
* -- column.3.type = VARCHAR
* -- column.4.name = VIEW
* -- column.4.type = VARCHAR
* -- column.5.name = AMOUNT
* -- column.5.type = DECIMAL
* -- column.5.precision = 9
* -- column.5.scale = 2
*
* -- thriller.print-tuple-member-separately = true
* -- thriller.header-tuple-separator = |
*/
SELECT
{[Actual]}
ON COLUMNS,
Non Empty(
Generate(
{Order(Uda([Market],"Major Market"),[Market].CurrentMember.MEMBER_NAME)}
,CrossJoin({[Market].CurrentMember},Union(CrossJoin(Descendants([Profit],[Measures].Levels(0))
,CrossJoin(Descendants([Year],[Year].Levels(0)),{[100]}))
,Union(CrossJoin(Descendants([Total Expenses],[Measures].Levels(0))
,CrossJoin(Descendants([Year],[Year].Levels(0)),{[100]}))
,CrossJoin(Descendants([Inventory],[Measures].Levels(0))
,CrossJoin(Descendants([Year],[Year].Levels(0)),{[200]})))))
)
)
ON ROWS
FROM Sample.Basic
Again, as a recap, the comment section at the top is used to provide specifically crafted ‘hints’ about how to map the output. Notice at the end of the comment section are some new parameters such as thriller.print-tuple-member-separately = true. This particular new option tells Thriller to break apart tuples so they are distinct columns (as opposed to joined together).
So let’s drop the driver into a generic JDBC tool such as RazorSQL and see what happens:
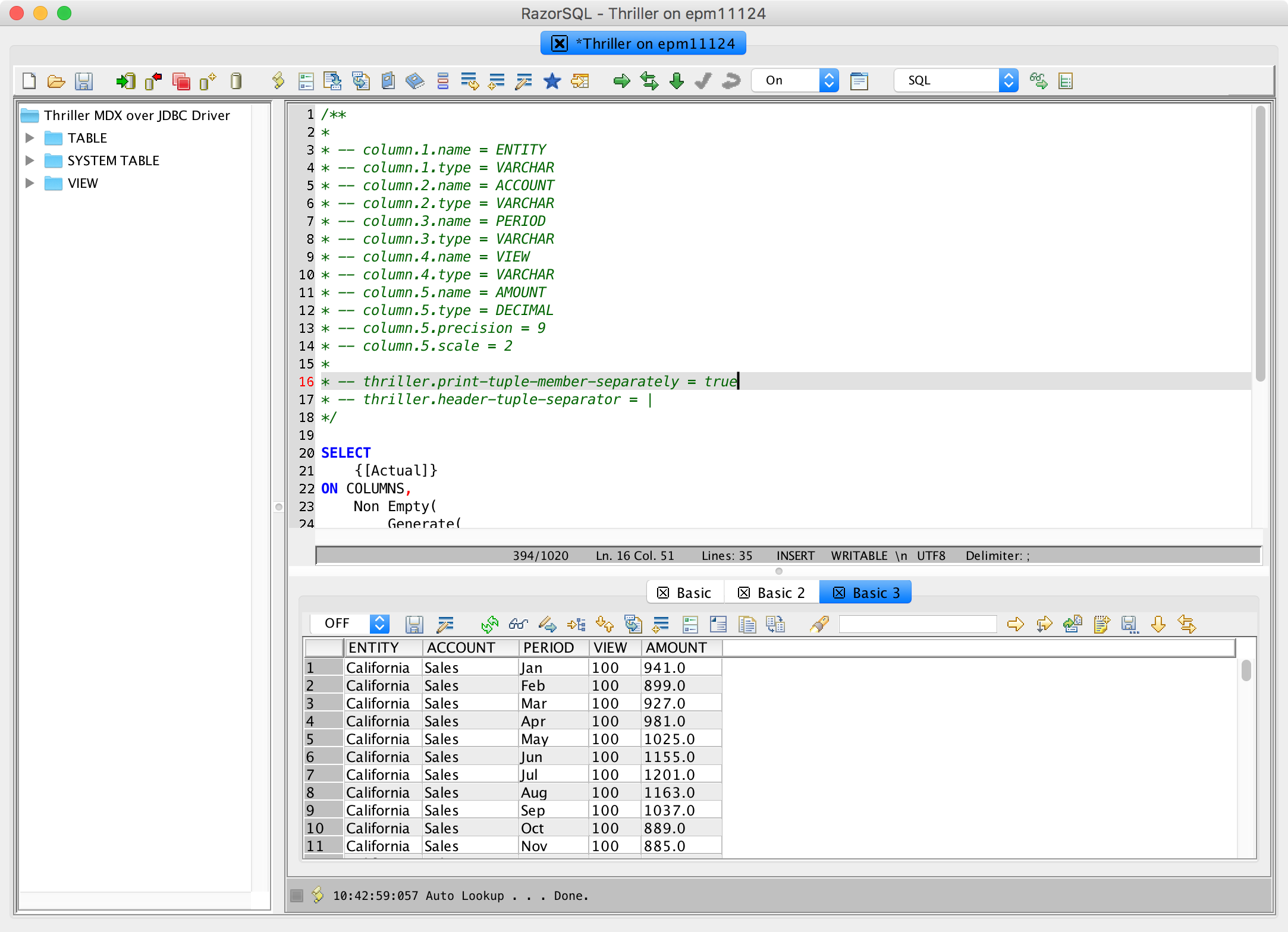
Results of executing MDX query using Thriller driver
As you can see, we just type the normal MDX query, preceded with the mapping info, then execute it as normal. The data we’re seeing is coming straight out of the Sample/Basic database. I think it’s even just the default data for that cube as well.
In case you are feeling adventurous, get the driver, and need to set it up, here’s what my driver/connection configuration for this server/cube looks like:

RazorSQL connection configuration
As you can see, there’s the connection parameters, the driver file, and a special JDBC URL that points to my Essbase server and a particular cube.
As with several of the other tools I’ve worked on (Vess et al.), I still classify Thriller as an “interesting” tool/side-project. It certainly works, and I think it could have some interesting use cases inside of tools such as ODI, FDMEE, and others. It’s still a little rough around the edges but feel free to contact me if you’d like a copy to play with.