We’ve made some enhancements to the Next Generation Outline Extractor to incorporate user feedback and requests. The main improvement to this newest release, version 2.1.3, is with the way that relational database extractions are handled. More specifically, the storing of relational credentials has been improved so that they are no longer stored in cleartext. This will lead to improved security for organizations using this functionality in their automation. Additionally, the configuration for relational extractions has been simplified a bit. There is now no longer a need to edit the persistence.xml file, rather, everything is stored in the main properties file.
As part of this post, I want to go over how the new functionality works, including a full “soup to nuts” use case. I think a lot of people use the outline extractor for “one-off” extractions, although a lot of people might be unaware that it can just as easily be used to quite easily automate extractions.
So, let’s dive in. I’m going to be using an internal build (i.e., running the extractor directly from my Java IDE), which is why the version is listed as “internal”. Also, I’m running on a Mac, where the UI looks a little different. The main difference is with the rendering of the tabs. On Windows the tabs for the UI are on the left side. However, on a Mac this is curiously rendered on the left side but the tabs are not rotated. So don’t be alarmed by the funky UI – it works fine and looks “normal” on Windows.
First, we launch the extractor’s UI. We’re going to create a new extraction definition:
Creating a new Essbase Extraction
Next, we’ll choose the source of the outline data. For this I’m just going to use the Essbase API. Note that the “MaxL” extraction can be much, much faster, assuming your version of Essbase supports it.
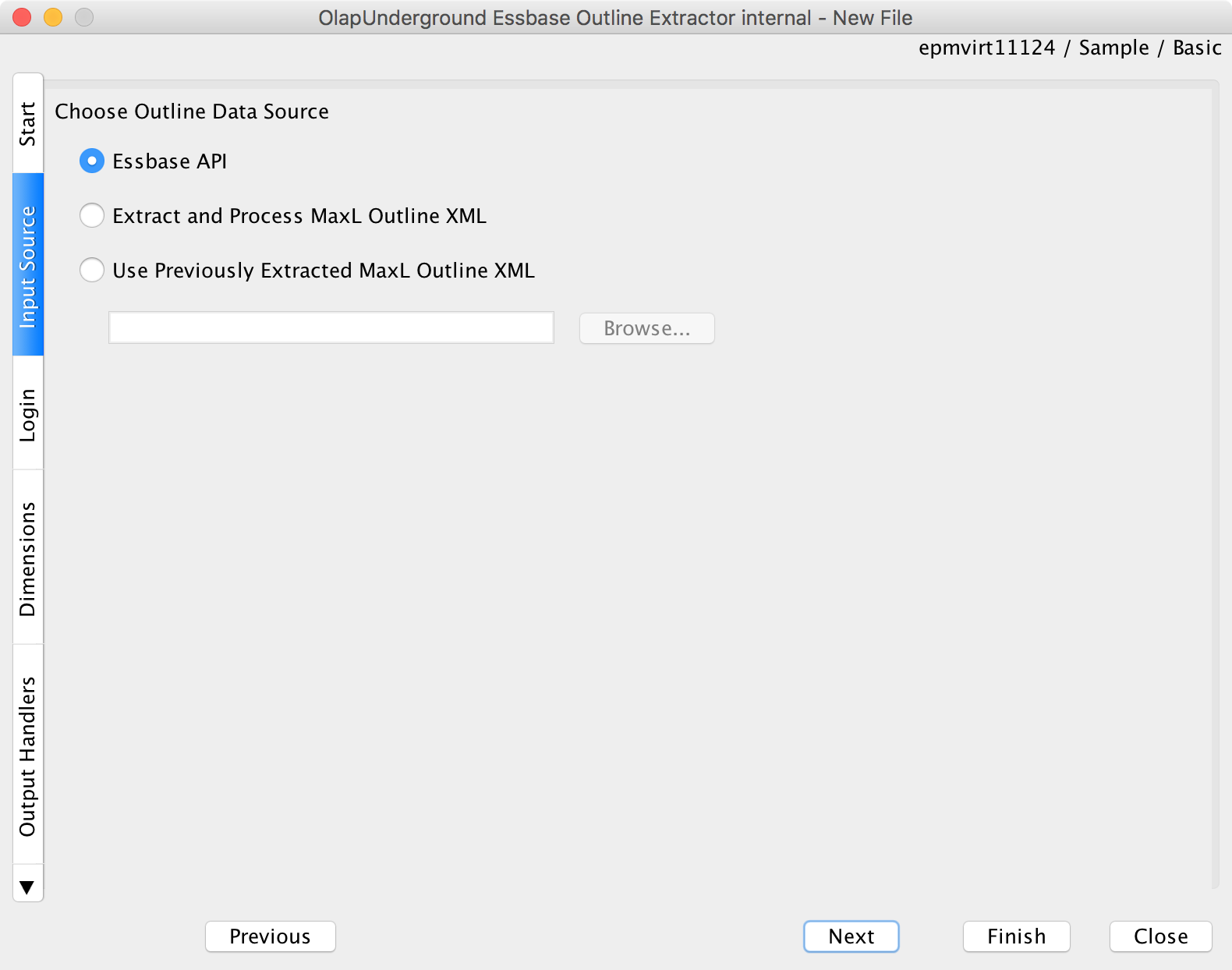
We’ll extract using the Essbase API (note: MaxL can be much faster)
We’ll login to an Essbase server and choose a cube:
Choose an Essbase server/cube
Then choose any/all dimensions to extract:
Choose one or more dimensions
Now we can choose our extractor(s). As this post is focused on the relational extraction, I’ll just choose the Relational Cache Writer only:
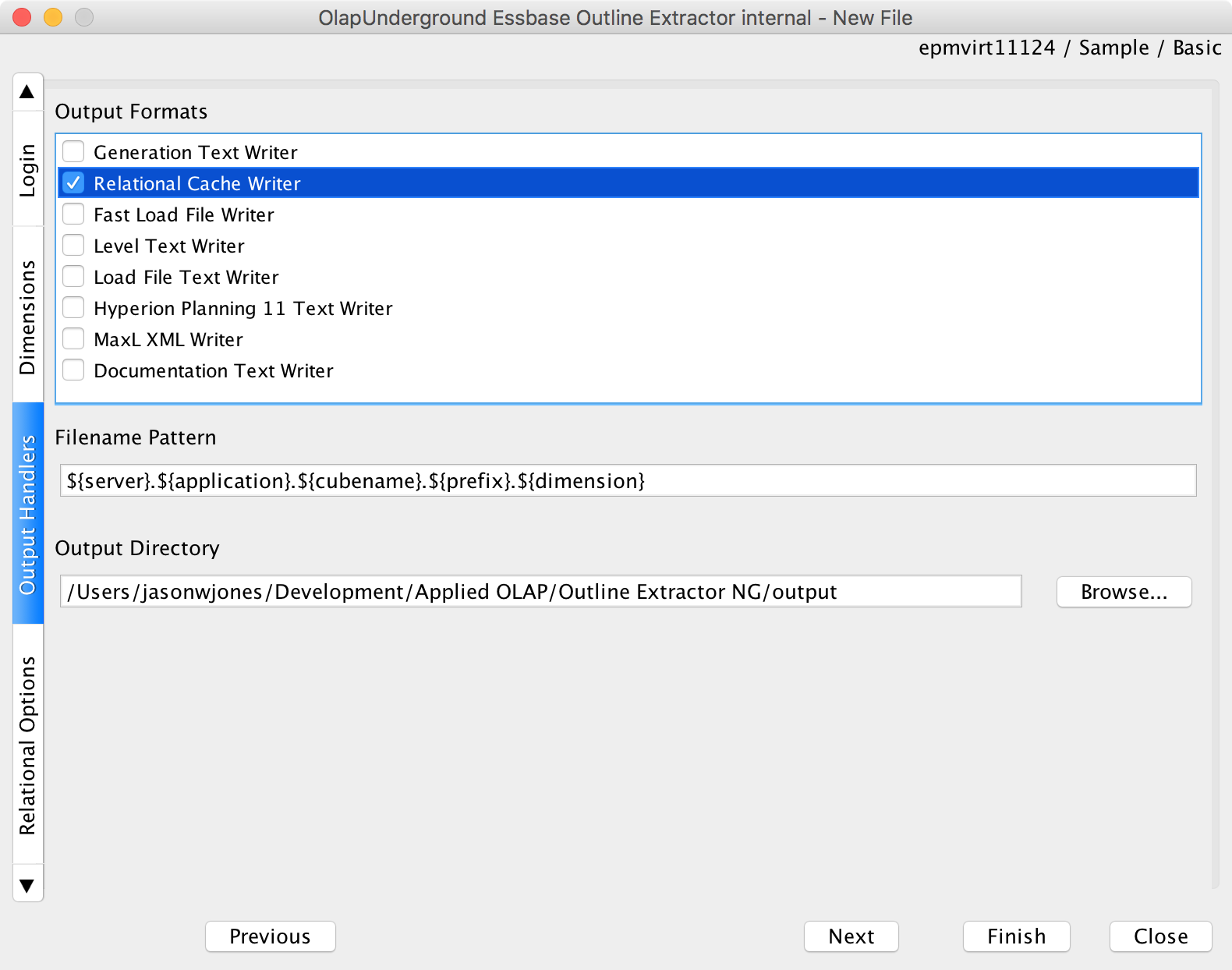
Pick the relational cache writer
Now we need to define the relational configuration. You’ll notice that this is referred to as the “Hibernate” properties. Hibernate is a very widely used Java library that helps map from object oriented programming paradigms to a relational database. We need specify the dialect (there are different dialects for each database type, such as SQL Server, MySQL, Oracle, and others), the driver class, the JDBC URL, and the credentials. Note that each type of database has it’s own JDBC URL syntax and driver. If you need help with your database type, you can typically just google for JDBC plus your database type to get the proper settings.

Configure relational settings
Next we’ll want to press Commit & Test so we can verify we have the database connection information correct. This will actually create the tables on the target schema that will be used to store the member information. You can see here that the test was successful:
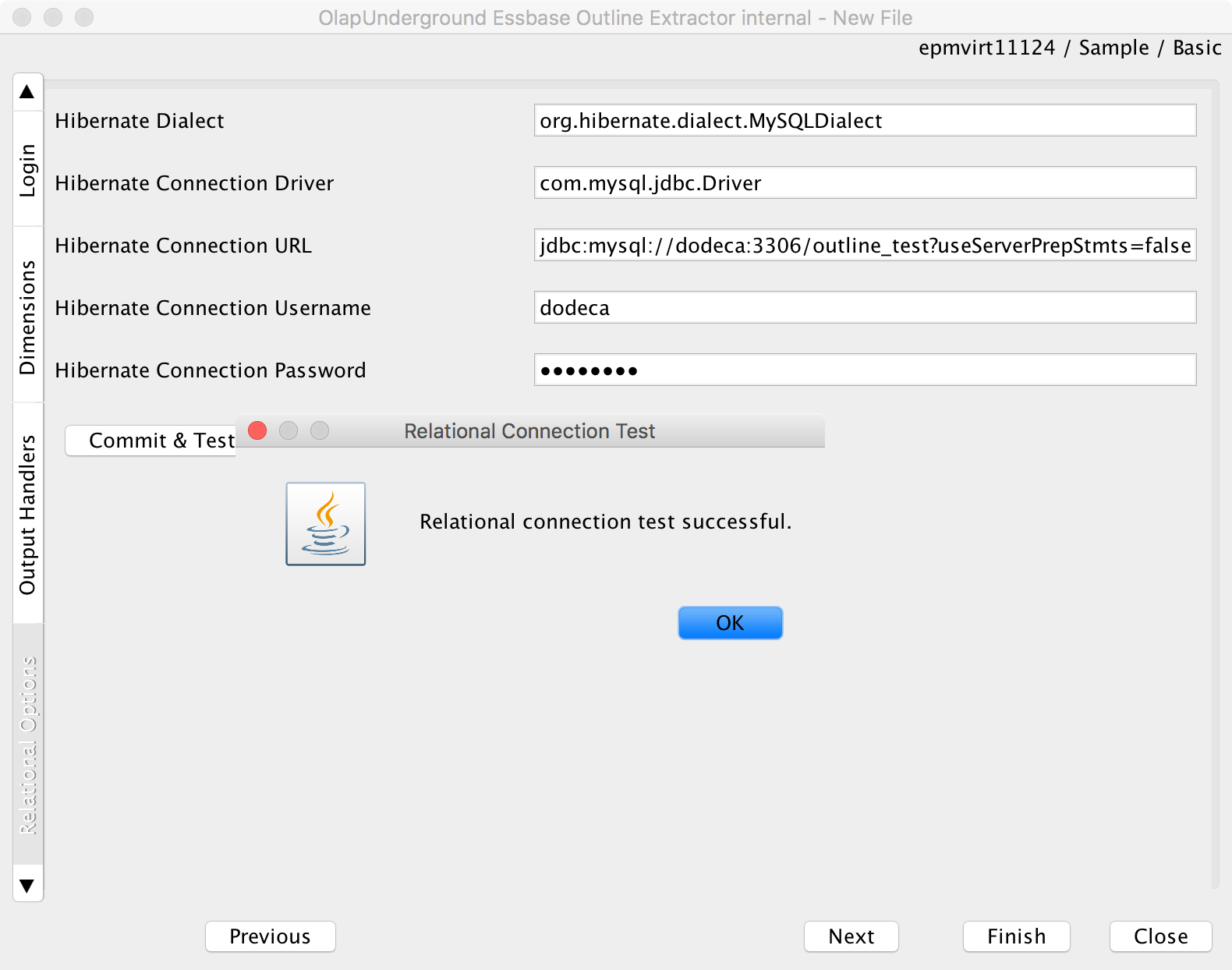
Results of a Commit & Test if successful
Switching over for a minute to my JDBC tool (RazorSQL), I can connect to my database server and see that indeed, the tables are created properly in the target schema:
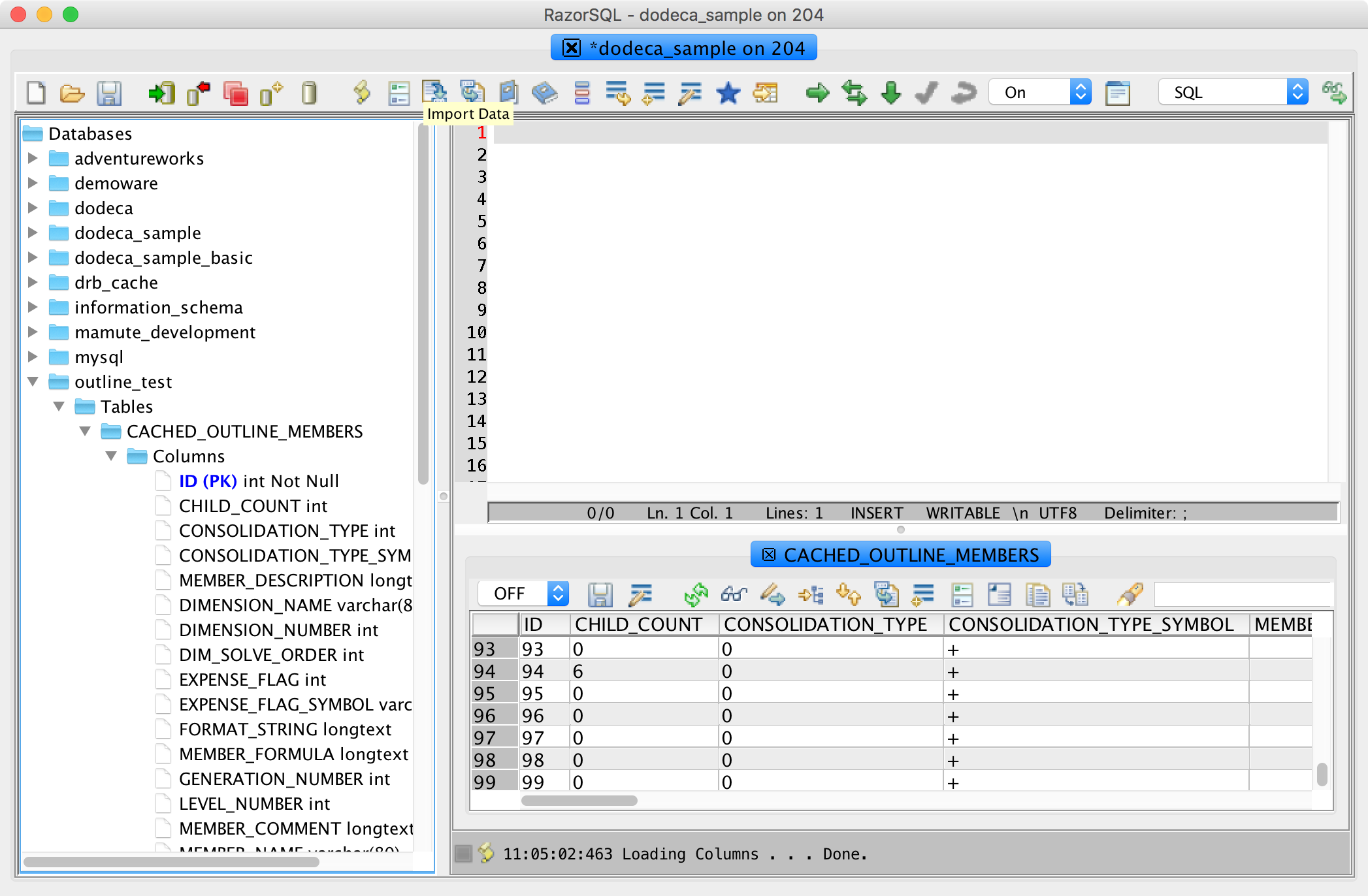
Checking the tables in a JDBC tool
Back in the outline extractor, I can move forward to the options tab (there are no options for the relational extractor, so we can just skip ahead here):
No options to configure on this writer type
We can just accept all the defaults here on the Performance settings:
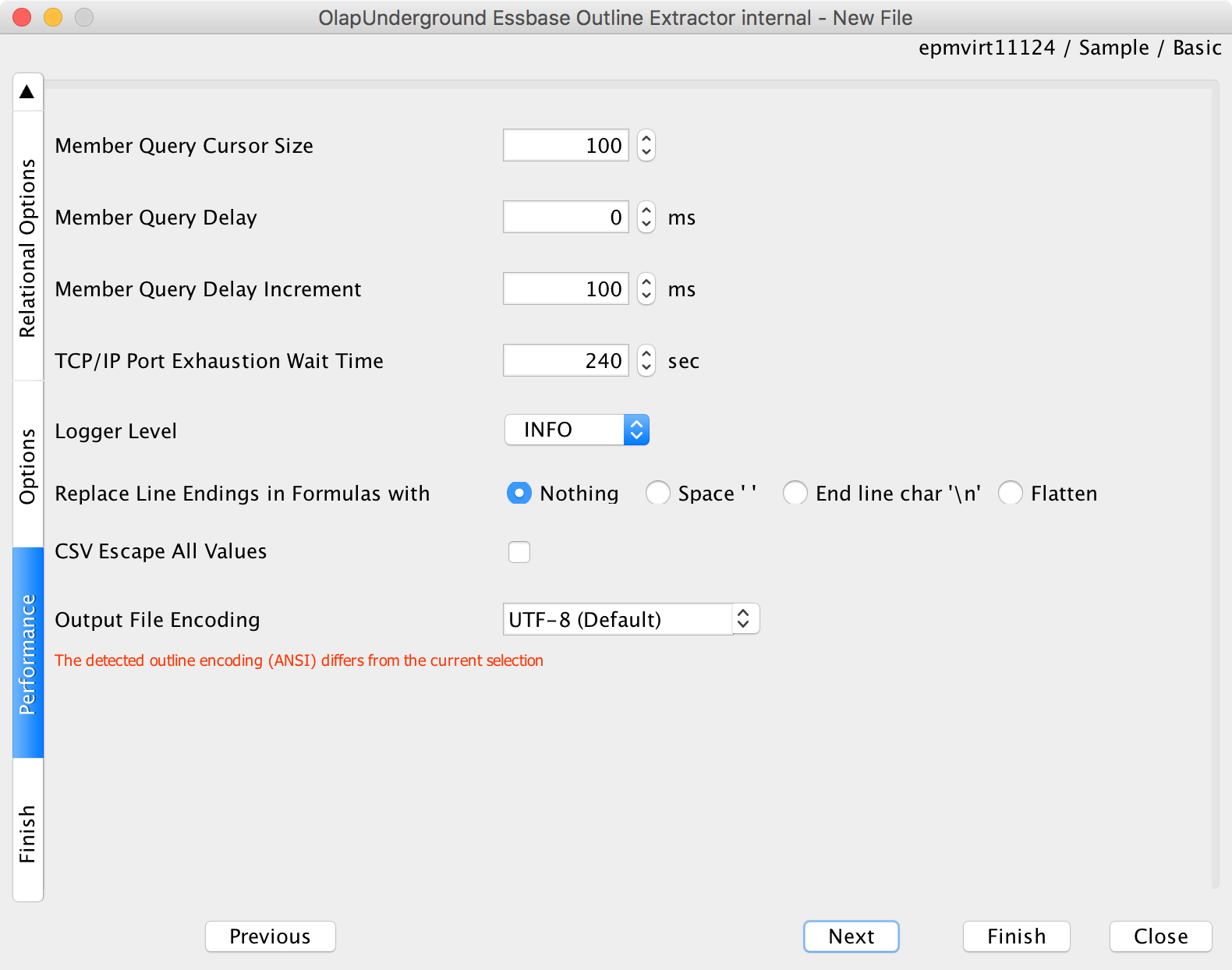
General extraction options (all default)
Now we’re on the pre-extraction screen. There are a couple of things to do here:
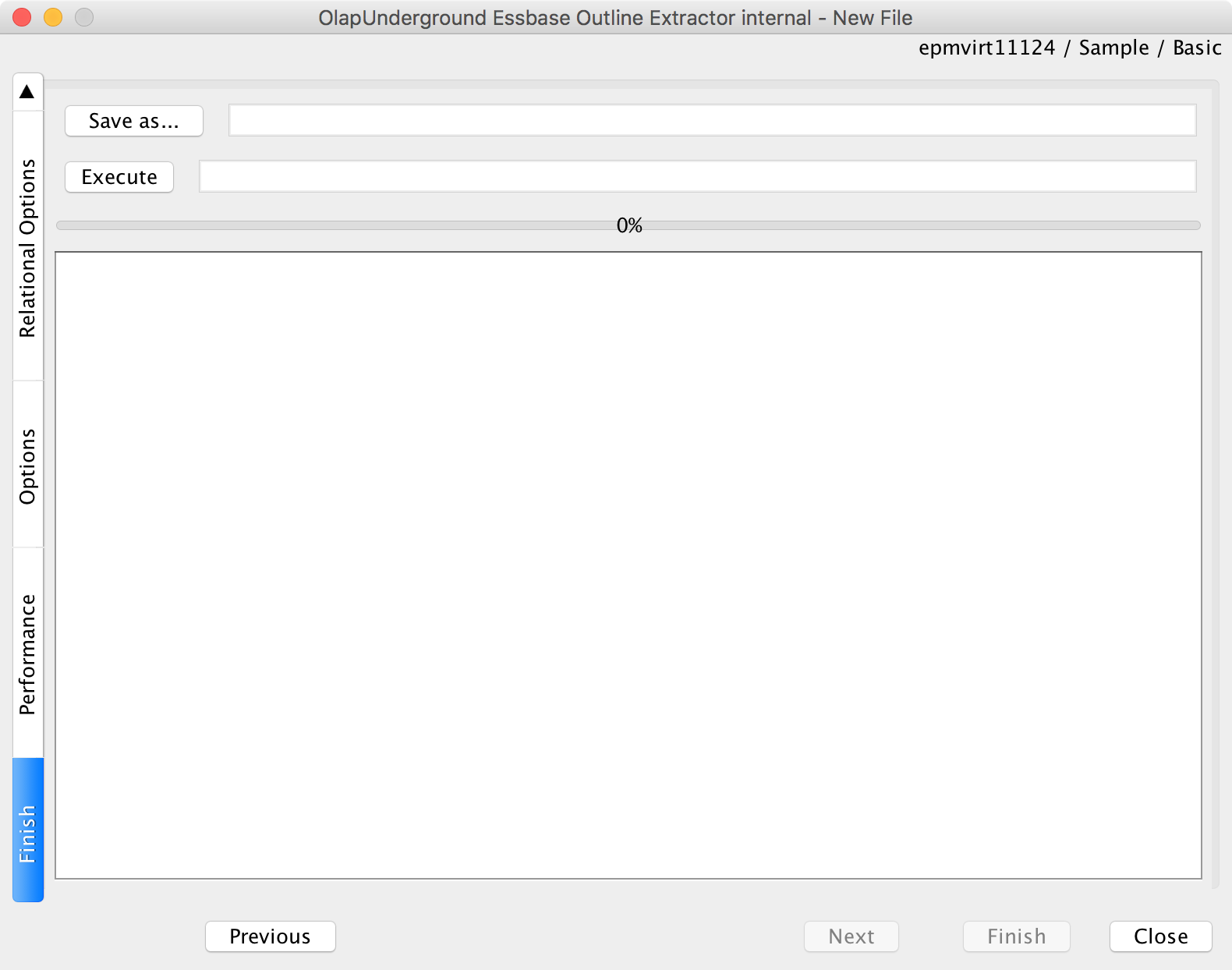
Pre-execution screen. Execute to run, Save as to save configuration
First, we can execute the extraction to perform it right now. After having performed the one-off extraction, I decide that I like it and I want to save the configuration so that I can use it again later. Therefore, I will click on the “Save as…” button and choose the name of a properties file to save to.
Let’s go check out what got saved into the properties file:
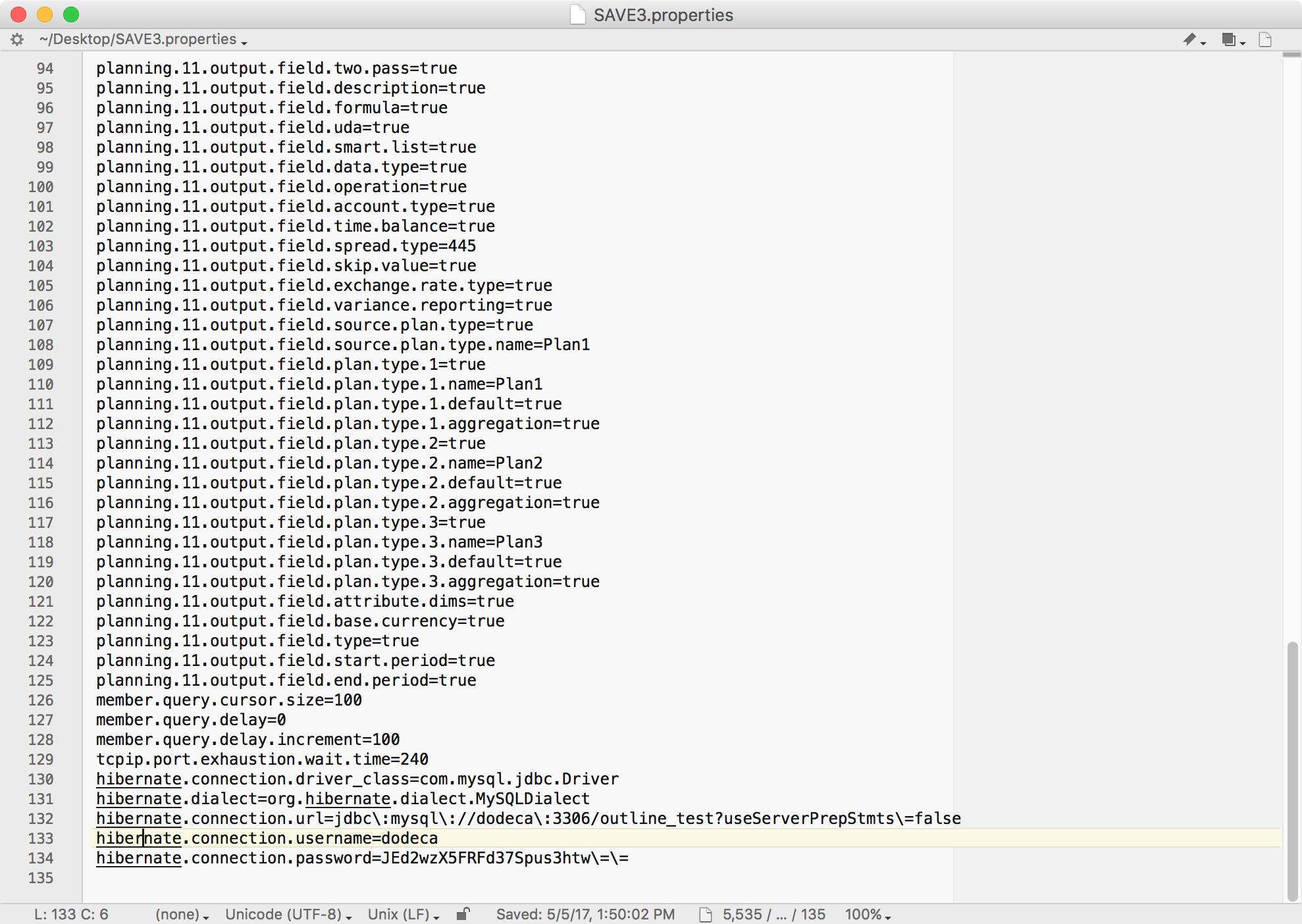
Contents of extraction configuration
You may notice at the end of this file, some Hibernate settings. This is the new part, as these settings weren’t in this file before, they were in a separate XML file that had to be managed. You can see that the extractor has placed in the driver type, dialect, and other connection information so that we can use it on a future extraction run. Also, the password is encrypted.
Now let’s run the extraction again and we’ll choose the properties file, indicating that we want to use the same exact settings from before (as specified in the file) to perform the extraction:
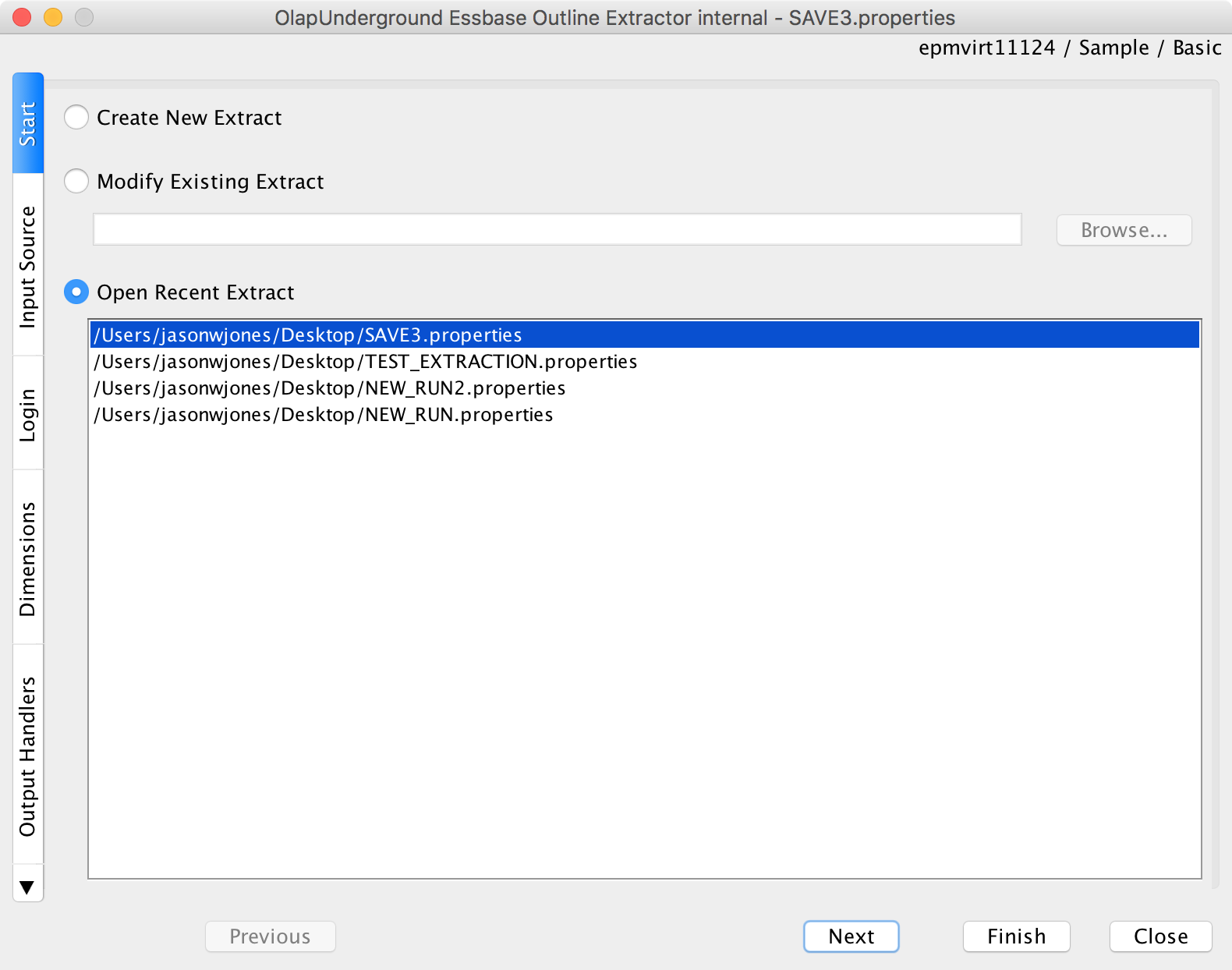
Running again, this time selecting an existing extraction configuration
Running through with the loaded properties file is exactly the same as before, just that all of the fields are pre-loaded for us. Perhaps more importantly, however, is that we can use the properties file to run the extractor on the command line. Let’s take a look at that.
The extractor now ships with an additional shell script (olap-underground-outline-extractor.sh) that helps setup a command-line extraction for Unix systems. It previously included a file that worked on Windows, now it ships both. Here is a screenshot of that file:
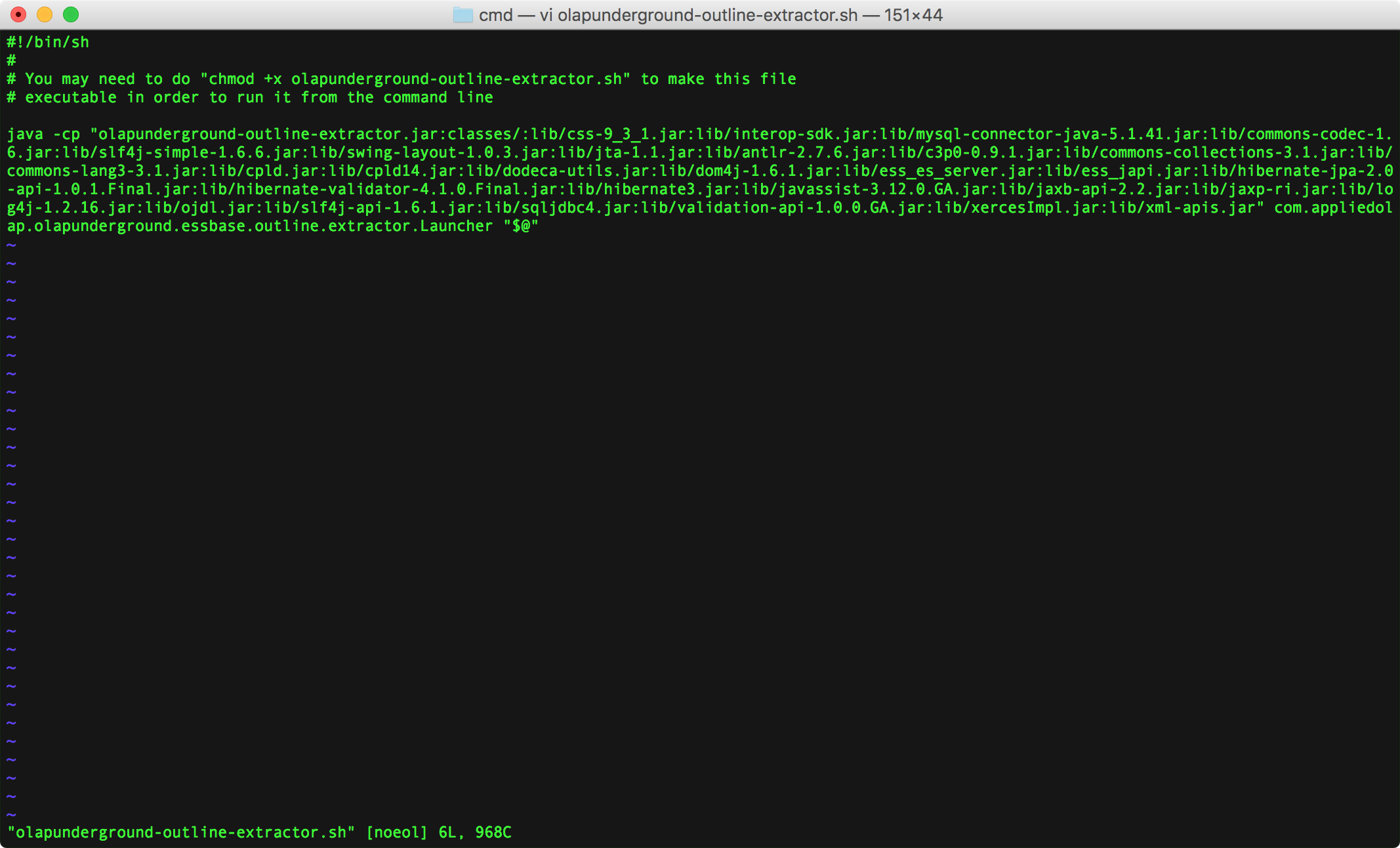
Command line outline extraction helper for Unix systems
There’s not much going on here except that the extractor is run using the java command, and all arguments passed to this script are handed off to the extractor.
Let’s go ahead and run this script and specify the properties file from earlier:
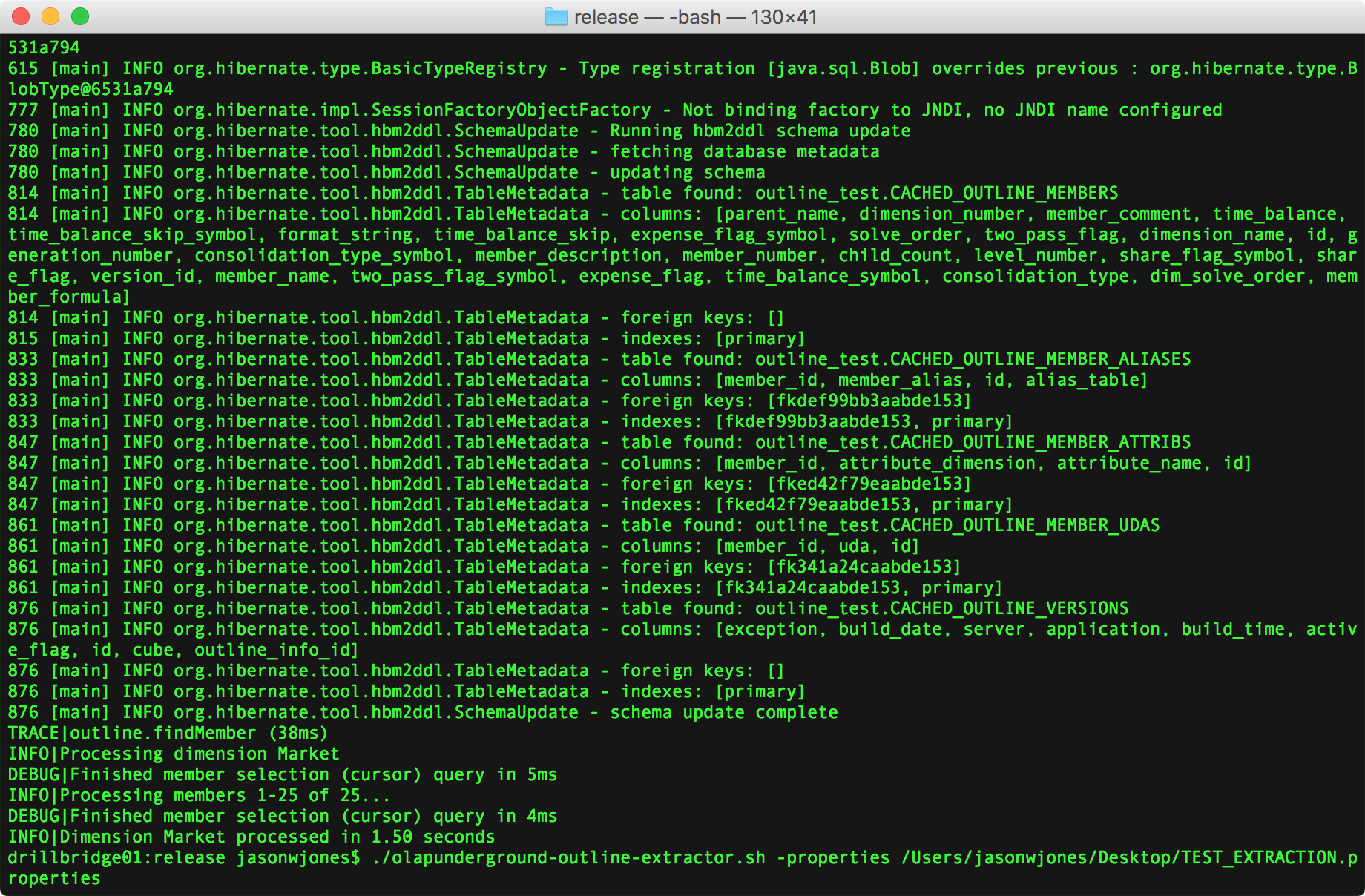
Outline extractor command line results and example
You can see that I actually already ran the script but then for convenience just displayed the command-line I used at the bottom. The format to run with a properties file is ./olapunderground-outline-extractor.sh -properties name-of-props-file.properties.
If you care to read the output, you may notice that the extraction ran successfully, and as defined earlier, was able to use the specified strategy to extract the Market dimension and place its contents into the tables in the schema we created earlier.
Wrapping Up
The Next Generation Outline Extractor is a completely free utility that is supported, developed, and enhanced by the Applied OLAP team. It has been downloaded tens of thousands of times by many people in the EPM community.
I hope you enjoyed both this improvement to the outline extractor as well as this example of how to use this feature either for a one-off extraction, your automation, or both. The outline extractor continues to evolve and improve based on feedback from the community and users.
Release Note: This newest version of the Outline Extractor is not officially released at the moment. I’ll be released to the Applied OLAP website in the next day or two.
is it supported by java1.8 instead of java 1.6?
Yes, it should run just fine in Java 1.8.