I’ve been wanting to write this post for awhile. Like, for months. Some time ago I took an in-depth look at profiling the performance (duration-wise) of an automated system I have. The system works great, it’s worked great, I don’t need to touch it, it just does its thing. This is the funny thing about systems that live in organizations: some of the rather inglorious ones are doing a lot of work, and do it reliably. Why reinvent the wheel and risk screwing things up?
{kind=link}
Well, one reason is that you need to squeeze some more performance out of that system. The results of my profiling efforts showed that the process was taking about an hour and a half to run. So, considering that the processing of the data is an hour behind the source system (the source system drops off text files periodically for Essbase), and it takes an hour and a half to run, the data in the cubes is some two and a half hours behind the real world numbers in the original system.
So, first, a little background on what kind of processing we have here. The gist of how this particular system works is that a mainframe manages all of the data, and certain events trigger updated files to get delivered to the Essbase server. These files are delivered at predictable intervals, and automation jobs are scheduled accordingly (about an hour after the text files are scheduled to be delivered, just to be on the safe side). The data that comes in is typical financial data — a location, a time period, a year, an account, and an amount.
Pretty simple, right? Well, there are about twenty cubes that are financial in nature that are modeled off of this data. The interesting thing is that these cubes represent certain areas or financial pages on the company’s chart of accounts. Many of the pages are structurally similar, and thus grouped together. But the pages can be wildly different from each other. For this reason, it was decided to put them in numerous cubes and avoid senseless inter-dimensional irrelevance. This keeps the contents of the cubes focused and performance a little better, at the expense of having to manage more cubes (users and admins alike). But, this is just one of those art versus science trade-offs in life.
Since these cubes add a “Departments” dimension that is not present in the source data, it is necessary to massage the data a bit and come up with a department before we can load the raw financial data to a sub-cube. Furthermore, not all the cubes take the same accounts so we need some way to sort that out as well. Therefore, one of the cubes in this process is a “staging” database where all of the data is loaded in, then report scripts are run against certain cross sections of the data, which kick out smaller data files (with the department added in) that are then loaded to the other subsequent cubes. The staging database is not for use by users — they can’t even see it. The staging database, in this case, also tweaks the data in one other way — it loads locations in at a low level and then aggregates them into higher level locations. In order to accomplish this, the staging database has every single account in it, and lots of shared members (accounts can be on multiple pages/databases).
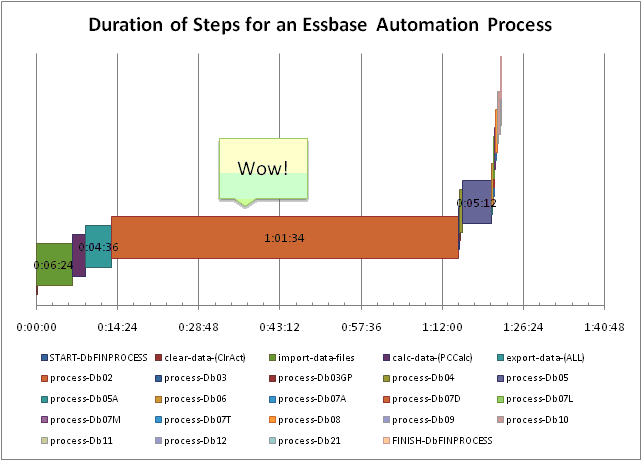
That being said, the database is s highly sparse. For all of these reasons, generating reports out of the staging database can take quite a bit of time, and this is indicated as the very wide brown bar on the performance chart linked above. In fact, the vast majority of the total processing time is just generating reports out of this extremely sparse database. This makes sense because if you think about what Essbase has to do to generate the reports, it’s running through a huge section of database trying to get what it wants, and frankly, who knows if the reports are even setup in a way that’s conducive to the structure of the database.
Of course, I could go through and play with settings and how things are configured and shave a few seconds or minutes off here and there, but that really doesn’t change the fact that I’m still spending a ton of my time on a task, that quite simply, isn’t very conducive to Essbase. In fact, this is the kind of thing that a relational database is awesome at. I decided, first things first, let’s see if we can massage the data in SQL Server, and load up the databases from that (and get equivalent results).
The SQL Server staging database is relatively simple. There is now a table that will have the data loaded to it (this is the data that was loaded to the staging cube with a load rule). The other tables include a list of financial pages (these are the departments on the sub-cubes, so to speak), a table for the list of databases (you’ll see why in a minute), a table for linking the departments/pages to a particular database, a table linking accounts to departments (pages), a page-roll table to manage the hierarchy of how pages aggregate to “bigger” pages, and a location/recap table that links the different small locations to their bigger parent locations (this is the equivalent of the location summing from the original staging database).
With all these tables in place, it’s time to add a few special views that will make life easier for us (and our load rules):
SELECT
D.database_name
, P.physical_page
, A.account
, K.div
, K.yr
, K.pd
, K.amt
FROM
account_dept AS A INNER JOIN
jac_sum_vw AS K ON A.account = K.account INNER JOIN
page P ON A.G_id = P.G_id INNER JOIN
page_database AS G ON A.G_id = G.G_id INNER JOIN
dbase AS D ON G.database_id = db.database_id
Obviously I didn’t provide the schema for the underlying tables, but this still should give you a decent idea of what’s going on. There’s another view that sits on top of this one that takes care of the summing of locations for us, but it’s structurally similar to this one, so no surprises there. What I end up with here is a view that has columns for the database name, the department, the account, location, year, period, and the amount. So not only is this perfect for a fact table down the road when I convert this to EIS, I can also use the exact same view for all of my databases, and a very similar load rule in each database that simply references a different database.
This all took a day or two to setup, but after I started getting data how I wanted, I got pretty stoked that I was well on my way to boosting performance of this system. One of the nice things about the way it’s setup in the relational database is also that it’s very flexible — extra databases, departments, locations, and anything else can be added to one central place without too much trouble.
Interestingly enough, this entire system is one that’s been in production for years but the “test” copy of things was sort of forgotten about and completely out of sync with production. Since I was getting closer to the point where I was ready to load some cubes, I needed to sync test to prod (oddly enough) so I could do all testing without hosing things up. Basically I just copied the apps from the production server to the test server with EAS, copied the existing automation folder, changed some server names and passwords (which were all hard-coded, brilliant…), and was pretty much good to go. On a side note, I took the opportunity to rewrite the automation in modular, test-ready form (basically this involved cleaning up the old hard-coded paths and making it so I could sync test to prod much easier).
My next step was to design a load rule to load data up, to make sure that the structure of the tables and views was sufficient for loading data. I did a normal SQL load rule that pulled data from the view I setup. The load rule included some text replacements to adapt my version of departments to the actual alias name in the database, but otherwise didn’t need anything major to get working. I loaded one period of data, calculated, saw that I was off a bit, researched some things, tweaked the load rule, recalculated, and so on, until finally the numbers were tying out with what I was seeing. Not bad, not bad at all.
After this basic load rule was working correctly, I started gutting the automation system to clean things up a bit more and use the new load rule (with the old calcs). After I felt good about the basic layout of things and got to the point where I was ready to copy this out to the other 18 or however many cubes. Then I put some hooks in the automation to create a log file for me, so I can track performance.
For performance profiling, I used a technique that I’ve been using for awhile and have been quite happy with. I have a small batch file in the automation folder called essprof.bat that has this in it:
@For /f "tokens=2-4 delims=/ " %%a in ('date /t') do @set FDATE=%%c-%%a-%%b
@echo %2,%FDATE% %TIME% >> %1
Basically when you call this file from another batch file, you tell it what file you want to append the data to, what the step should be named, and it takes care of the rest. Here is how I might call it from the main automation script:
CALL essprof.bat %PROFFILE% START-PROCESS
The PROFFILE variable comes from a central configuration file and points to a location in the logging folder for this particular automation set. For this particular line, I would get output like the following:
START-PROCESS,2009-07-31 8:57:09.18
The For loop in the batch file parses the DOS/shell date command a little bit, and together with the TIME variable, I get a nice timestamp — one that, incidentally, can be read by Excel very easily.
So what’s this all for? As I did in the original performance chart, I want to profile every single step of the automation so I can see where I’m spending my time. Once I filled out the rest of the load rules and ran the process a few times to work out the kinks, I now had a good tool for analyzing my performance. Here is what one of the initial runs looked like:
start-db02-process 10:54 AM finish-db02-process 10:54 AM start-db03-process 10:54 AM finish-db03-process 10:57 AM start-db03GP-process 10:57 AM finish-db03GP-process 10:58 AM start-db04-process 10:58 AM finish-db04-process 11:13 AM start-db05-process 11:13 AM finish-db05-process 11:13 AM start-db06-process 11:13 AM finish-db06-process 11:13 AM start-db07A-process 11:13 AM finish-db07A-process 11:13 AM start-db07D-process 11:13 AM finish-db07D-process 11:14 AM start-db07L-process 11:14 AM finish-db07L-process 11:14 AM start-db07M-process 11:14 AM finish-db07M-process 11:14 AM start-db07T-process 11:14 AM finish-db07T-process 11:14 AM start-db08-process 11:14 AM finish-db08-process 11:14 AM start-db09-process 11:14 AM finish-db09-process 11:14 AM start-db10-process 11:14 AM finish-db10-process 11:14 AM start-db11-process 11:14 AM finish-db11-process 11:14 AM start-db12-process 11:14 AM
And how do we look? We’re chunking through most of the databases in about 20 minutes. Not bad! This is a HUGE improvement over the hour and a half processing time that we had earlier. But, you know what, I want this to run just a little bit faster. I told myself that if I was going to go to the trouble of redoing the entire, perfectly working automation system in a totally new format, then I wanted to get this thing down to FIVE minutes.
Where to start?
Well, first of all, I don’t really like these dense and sparse settings. Scenario and time are dense and everything else is sparse. For historical reasons, the Scenario dimension is kind of weird in that it contains the different years, plus a couple budget members (always for the current year), so it’s kind of like a hybrid time/scenario dimension. But, since we’ll generally be loading in data all for the same year and period at once (keep in mind, this is a period-based process we’re improving), I see no need to have Scenario be dense. Having only one dense dimension (time) isn’t quite the direction I want to go in, so I actually decided to make location a dense dimension. Making departments dense would significantly increase my inter-dimensional irrelevance so Location seems like a sensible choice — especially given the size of this dimension, which is some 20 members or so. After testing out the new dense/sparse settings on a couple of databases and re-running the automation, I was happy to see that not only did the DB stats look good, but the new setting was helping improve performance as well. So I went ahead and made the same change to all of the other databases, then re-ran the automation to see what kind of performance I was getting.
End to end process time was now down to 12 minutes — looking better! But I know there’s some more performance out there. I went back to the load rule and reworked it so that it was “aligned” to the dense/sparse settings. That is, I set it so the order of the columns is all the sparse dimensions first, then the dense dimensions. The reason for this is that I want Essbase to load all the data to a single data block that it can, and try to minimize the number of times that the data block is loaded to memory.
Before going too much further I added some more logging to the automation so I could see exactly when the database process started, when it ran a clearing calc script, loaded data, and calculated again.
Now I was down to about 8 minutes… getting better. As it turns out, I am using the default calculation for these databases, which is a CALC ALL, so that is a pretty ripe area for improvement. Since I know I’m loading data all to one time period and year, and I don’t have any “fancy” calcs in the database, I can rewrite this to fix on the current year and period, aggregate the measures and departments dimensions, and calc on the location dimension. By fancy, I’m referring to instances were a simple aggregation as per the outline isn’t sufficient — however, in this case, just aggregating works fine. I rewrote the FIX, tested it, and rolled it out to all the cubes. Total end to end load time was now at about four minutes.
But, this four minute figure was cheating a little since it didn’t include the load time to SQL, so I added in some of the pre-Essbase steps such as copying files, clearing out the SQL table, and loading in the data. Fortunately, all of these steps only added about 15 seconds or so.
I decided to see if using a more aggressive threads setting to load data would yield a performance gain — and it did. I tweaked essbase.cfg to explicitly use more threads for data loading (I started with four threads), and this got total process time down to just under three minutes (2:56).
As an aside, doing in three minutes what used to take 90 would be a perfectly reasonable place to stop, especially considering that my original goal was to get to five minutes.
But this is personal now.
Me versus the server.
I want to get this thing down to a minute, and I know I still have some optimizations left on the table that I’m not using. I’ve got pride on the line and it’s time to shave every last second I can out of this thing.
Let’s shave a few more seconds off…
Some of the databases don’t actually have a departments dimension but I’m bringing a “dummy” department just so my load rules are all the same — but why bring in a column of data I don’t need? Let’s tweak that load rule to skip that column (as in, don’t even bother to bring it in from SQL) on databases that don’t have the departments dimension. So I tweaked the load rule got the whole process down to 1:51.
Many of these load rules are using text replacements to conform the incoming department to something that is in the outline… well, what if I just setup an alternate alias table so I don’t even have to worry about the text replacements? It stands to reason, from an Essbase data load perspective, that it’s got to cycle through the list of rows on the text replace list and check it against the incoming data, so if I can save it the trouble of doing that, it just might go faster. And indeed it does: 1:39 (one minute, thirty nine seconds). I don’t normally advocate just junking up the outline with extra alias tables, but it turns out that I already had an extra one in there that was only being used for a different dimension, so I added my “convenience” aliases to that. I’m getting close to that minute mark, but of course now I’m just shaving tiny bits off the overall time.
At this point, many of the steps in the 90-step profiling process are taking between 0 and 1 seconds (which is kind of funny, that a single step starts, processes, and finishes in .3 seconds or something), but several of them stand out and take a bit longer. What else?
I tried playing with Zlib compression, thinking that maybe if I could shrink the amount of data on disk, I could read it faster into memory. In all cases this seemed to hurt performance a bit so I went back to bitmap. I have used Zlib compression quite successfully before, but there’s probably an overhead hit I’m taking for using it on relatively “small” database — in this case I need to get in and get out as fast as I can and bitmap seems to allow me to do that just a little faster, so no Zlib this time around (but I still love you Zlib, no hard feelings okay?).
Okay, what ELSE? I decided to bump the threads on load to 8 to see if I got more of a boost — I did. Total load time is now at 1:25.
The SQL data load using bcp (the bulk load command line program) takes up a good 10 seconds or so, and I was wondering if I could boost this a bit. bcp lets you tweak the size of the packets, number of rows per batch, and lock the table you’re loading to. So I tweaked the command line to use these options, and killed another few seconds off the process — down to 1:21.
Now what? It turns out that my Location dimension is relatively flat, with just two aggregated members in it. I decided that I don’t really need to calculate these and setting them as dynamic would be feasible. Since location is dense this has the added benefit of removing two members from my stored data block, or about 10 percent in this case. I am definitely approaching that area where I am possibly trading query performance just for a little bit faster load, but right now I don’t think I’m trading away any noticeable performance on the user side (these databases are relatively small).
Just reducing the data blocks got me down to 1:13 or so (closer!), but since there are now no aggregating members that are stored in the Location dimension, I don’t even need to calculate this dimension at all — so I took the CALC DIMs out of all the calc scripts and got my calc time down further to about 1:07.
Where oh where can I find just 7 more seconds to shave off? Well, some of these databases also have a flat department structure, so I can definitely shave a few seconds and save myself the trouble of having to aggregate the departments dimension by also going to a dynamic calc on the top level member. So I did this where I could, and tweaked the calcs accordingly and now the automation is down to about 1:02.
And I am seriously running out of ideas as to where I can shave just a COUPLE of more seconds off. Come on Scotty, I need more power!
Well, keeping in mind that this is a period process that runs numerous times during closing week, part of this process is to clear out the data for the current period and load in the newer data. Which means that every database has a “clear” calc script somewhere. I decided to take a look at these and see if I could squeeze a tiny bit of performance out.
I wanted to use CLEARBLOCK because I’ve used that for good speedups before, but it’s not really effective as a speedup here because I have a dense time dimension and don’t want to get rid of everything in it (and I think CLEARBLOCK just reverts to a normal CLEARDATA if it can’t burn the whole block). However, there were still some opportunities to tweak the clearing calc script a little so that it was more conducive to the new dense and sparse settings. And sure enough, I was able to shave .1 or .2 seconds off of the clear calc on several databases, giving me a total process time of……. 59.7 seconds. Made it, woot!
Along the way I tried several other tweaks here and there but none of them gave me a noticeable performance gain. One change I also made but seems to be delivering sporadic speed improvements is to resize the index caches to accommodate the entire index file. Many of the indexes are less than 8 megabytes already so they’re fine in that regard, some of them aren’t so I sized them accordingly. I’d like to believe that keeping the index in memory is contributing to better performance overall but I just haven’t really been able to profile very well.
After all that, in ideal circumstances, I got this whole, previously hour-and-a-half job down to a minute. That’s not bad. That’s not bad at all. Sadly, my typical process time is probably going to be a minute or two or longer as I adjust the automation to include more safety checks and improve robustness as necessary. But this is still a vast improvement. The faster turnaround time will allow my users to have more accurate data, and will allow me to turn around the databases faster if something goes wrong or I need to change something and update everything. In fact, this came in extremely useful today while I was researching some weird variances against the financial statements. I was able to make a change, reprocess the databases in a minute or so, and see if my change fixed things. Normally I’d have to wait an hour or more to do that. I may have optimized more than I needed to (because I have an almost unhealthy obsession with performance profiling and optimization), but I think it was worth it. The automation runs fast.
So, my advice to you: always look at the big picture, don’t be afraid to use a different technology, get metrics and refer to them religiously (instead of “hmm, I think it’s faster this way), try to think like Essbase — and help it do its job faster, and experiment, experiment, experiment.
Great story. Most of us would have quit at the 5 minute mark (and I have). It’s alway nice to see how someone goes about optimizing their environment. Thinking outside the box like you did can be a big help
Agreed and real tenacity!
I am really impressed with your approach. I don’t have much experience in Optimization but presently facing a serious issue which I think is related to the System performance rather than a real script issue. I created CalcAll script in the Develeopment which used to take about 1 hour to run but the same script when I migrated to Production is taking 12 hours to run. Can you suggest me some system checklist I should take care of before I go deep into the Script logic.