I had a little bit of time this weekend and dusted off Vess for some updates. I was able to greatly enhance the functionality and perhaps more important, widen the number of use cases that it could be used in.
I already wrote about a use case previously: using SQL to create a substitution variable. Vess supports fully symmetric substitution variable updates. That is to say, you can create, read, update, and delete substitution variables on your Essbase server just by changing the data in the proper table. So just to elaborate on my thoughts on the previous post, I think there are some nice use cases here. Of course, there’s nothing wrong with MaxL, but if you have an instance where you are dumping substitution variables via MaxL and scraping the ASCII art off of them in order to get to the real variable values, Vess offers a cleaner approach.
As of now, Vess also provides a window in to a whole slew of properties on various Essbase objects: server, application, and database. Here’s a view of some database properties (as shown in a generic JDBC GUI with Vess configured as a driver):
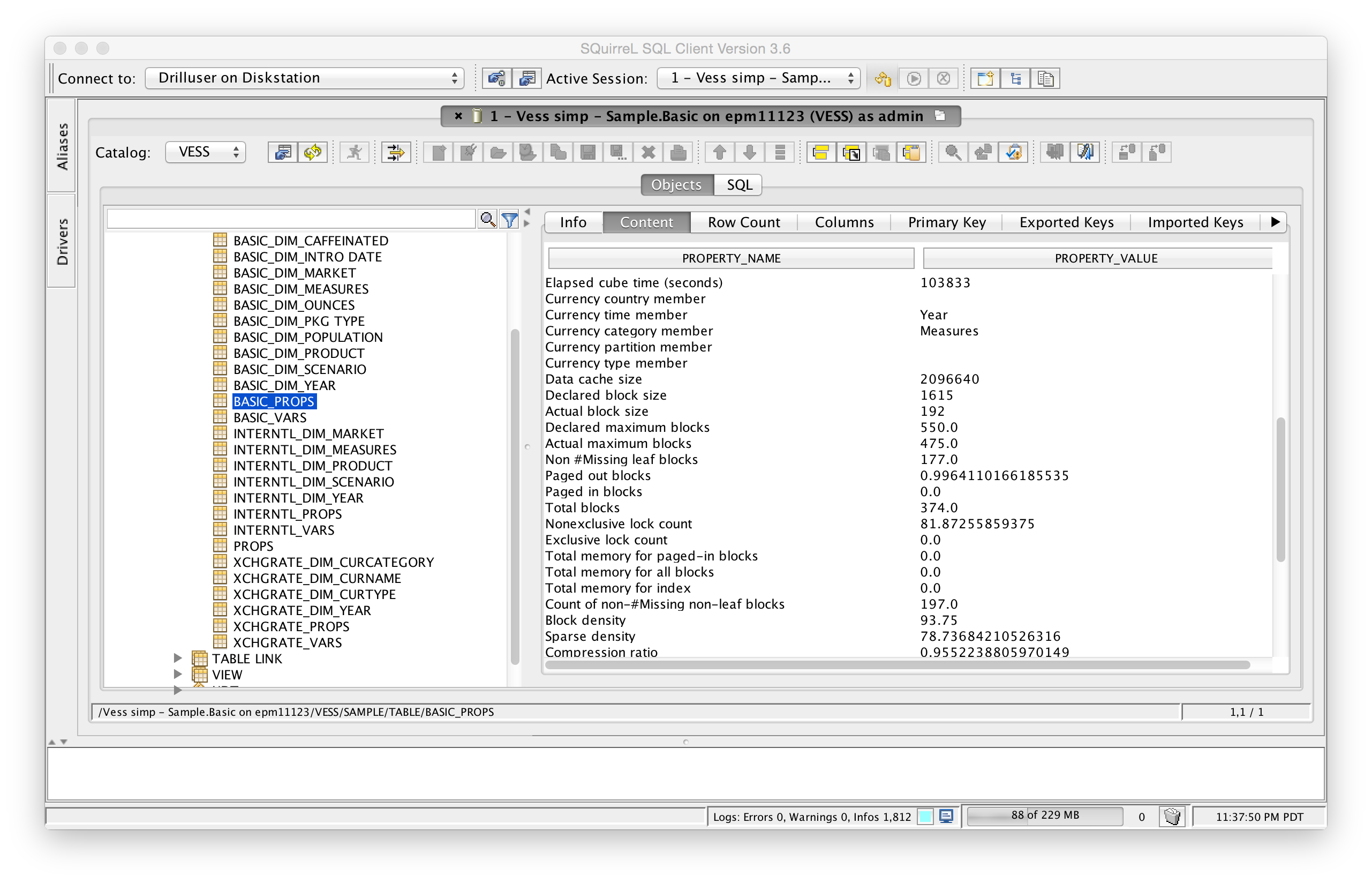
There’s a use case here too. I know of more than a few people that are dumping database stats using MaxL (such as to monitor a database/server stats over time). So instead of running a script, dumping to a file, parsing that out (or whatever), you could slam the data directly into SQL (using ODI or just some tool that can execute SQL statements).
Next up, Vess models tables for the various dimensions in a cube. This is not unlike how ODI would create a model of a cube: one table per dimension. Here’s a view of some information from Sample/Basic:
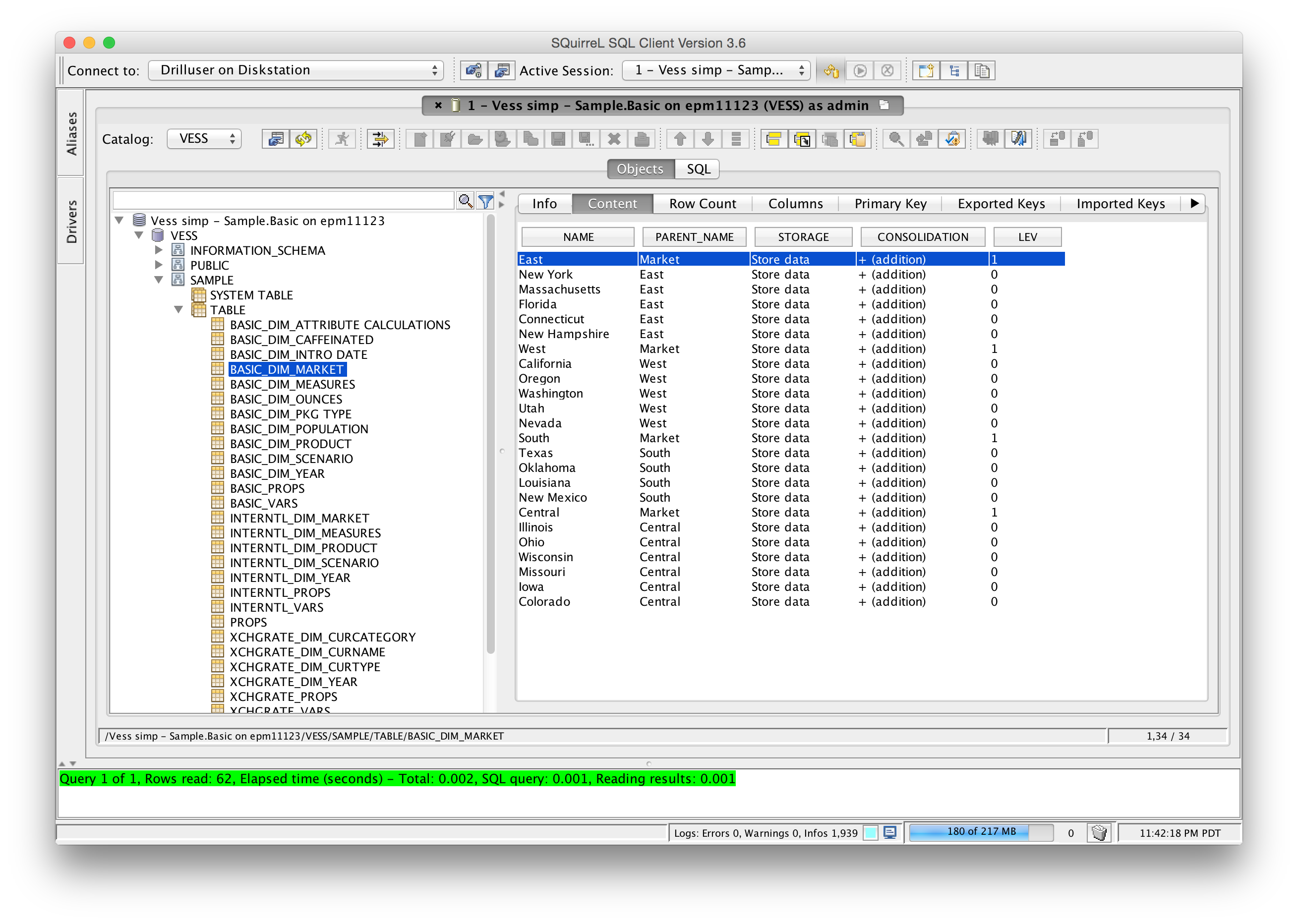
Outline functionality in Vess is not symmetric: you can read but updates are disabled for now. The use case here is that you could pull outline information without needing to use ODI (or something else) and possibly if you are using the Essbase Outline Extractor in your automation. Since Vess is already a fully functional SQL database, you could pretty easily do some interesting things like just grabbing all of the level-0 members in an outline (“SELECT * FROM SAMPLE.BASIC_DIM_MARKET WHERE LEVEL = 0”).
For now, Vess supports data loads to a cube (look mom, no load rules!). I wrote about this before too. Data reads are turned off for now (as in, you can INSERT but SELECT always returns nothing). It’s a bit of an interesting issue when you want to map this into a relational model.
Lastly, I started writing up the ODI technology for Vess. I think this is an absolute win for Vess because it would mean that you could build a nice clean technology/Knowledge Module that doesn’t have to use a bunch of Jython to glue things together: you can treat everything as a vanilla JDBC database model. No idea when this could be ready but you can rest assured that I’ll blog about it.