There’s a lot of excitement in the EPM world these days when it comes to REST APIs – and rightfully so. As a developer heavily invested in the EPM space I am excited about some of the possibilities these new APIs offer – and what they will offer in the future. But all of this great new REST API stuff can be quite daunting – how does it work, why should you care, where does it fit in with your overall architecture, and so on. And with ODTUG‘s Kscope18 just around the corner I thought it might be useful to write a primer – or a crash course of sorts – for the EPM professional on what all this REST API business is about. Also be sure to check out one of my presentations at Kscope this year as I will be discussing the OAC Essbase REST API, how to use it, what it does, and more. Continue Reading…
Drillbridge Plus 3.3.0 Release & Features
Drillbridge Plus (the licensed/supported version of Drillbridge) is officially released. This release introduces some great new features, enhancements, and bug fixes, including the following:
- User Parameters
- Download File Name
- Analytic Provider Services support
- Various drill report changes/enhancements
- UI/bug fixes/enhancements
User Parameters
The headline feature in this release of Drillbridge is support for the new “User Parameters” feature. This feature is configured on a per-report basis and provides a mechanism to prompt the drill-through user for additional input before executing the report. The values that the user provides are accessible as with any other variable in the final Drillbridge query syntax (in addition to their original drill-through POV). The user parameters feature is useful when you want your query to use additional detail/parameters that aren’t present in the dimensionality of the source system being drilled from.
A report can have an arbitrary number of user parameters associated with it. Each parameter has the following options available to configure:
- Name – defines the name of the parameter. This is shown to the user on the user parameter input page next to the input area.
- Description – description of the parameter. Shown to the user as the “help text” below the user parameter input area.
- Variable name – the variable that will be tied to the user’s input in the Drillbridge query. For example, if prompting the user for a particular account, the variable name might be “Account”, and usable in your Drillbridge expressions as the #Account variable.
- Input type – choose from a textbox input type or a drop-down selector. Another option is “textbox with auto-complete” which is a normal textbox input with auto-complete enabled, which will use the text or SQL query in the “possible values” definition.
- Preset value – a value to pre-fill or pre-select for the user, depending on the input type. Textboxes will be pre-filled with this value and drop-downs will pre-select it.
- Optional – whether the parameter is optional or not. If using textbox input, the user will not be required to enter a value. If using a drop-down, then one of the valid options for the user will be “nothing”.
- Default value – if the user parameter is optional and no value is specified, you may specify a default value (you may also elect to just handle null/empty values in your SQL/query, which should be more or less the same).
- Secure input – if using a textbox to input parameters, its input will be masked (as with a password input box).
- Possible values/query definition – You may define a list of values to place into the drop-down or to serve as auto-complete suggestions. You may also define a Drillbridge query that returns values to be used.
- Connection – If the “possible values” specification is a Drillbridge query, then you must set the SQL connection to use here, otherwise, leave it blank.
Analytic Provider Services support
Support for connecting to Essbase via Analytic Provider Services is now provided. On the Servers editor, define an APS server name or leave it blank to use the default embedded mode.
Download File Name
You can now use a Drillbridge query expression to define the name to use when a user downloads their drill-through results as an Excel or CSV file. By default, the name of the Drillbridge report itself with any spaces replaced by underscores is used as the download file name (appended with .xlsx or .csv as the case may be).
The Download File Name option allows for defining a normal Drillbridge expression that can be used to customize the file name to include tokens.
For example, the download file name for a Drillbridge report named “Transaction Detail” may have been Transaction_Detail.xlsx, but using the download file name feature in conjunction with tokens from the drill-through POV may now result in a download file name such as Transaction_Details_Jan_2017.xlsx.
Various drill report changes/enhancements
- Query row limit and query timeout options have moved to the general options page.
- You can now edit the internal description of a report
- You may now specify http:// or https:// as part of the server name when deploying a report. Previously, https:// was assumed and orgnanizations using Drillbridge over HTTPS had to manually edit the drill-through definition
- Enhancements to drillable columns. There is a new rendering type for drillable columns that renders with an arrow instead of a link. This is useful for reports with drillable columns where there are multiple drillable column definitions in the same column
- New Inline CSV file download. New option to turn on “inline” CSV downloads such that CSV output is shown directly in browser instead of being a download
- Autosum rows: new option to automatically sum all or some of the columns in the drill-through report
UI/bug fixes/enhancements
- You can sort connections/servers/reports by various columns, such as name, connection, and description
- Enhanced descriptions on various text fields in UI
- Fixes when deleting a server entry
There are no changes to the community edition of Drillbridge at this time. If you’d like a Drillbridge Plus demo or more information on how Drillbridge can help your organization, please don’t hesitate to contact Applied OLAP.
Dodeca Dynamic Build Example & Walkthrough
Today I’m going to walk through a multi-faceted Dodeca example that shows off several different concepts and techniques. We tend to conceptualize Dodeca applications and solutions in terms of making Essbase even better and today’s example is a perfect example of how we do that.
Think about it this way: your organization spends an enormous amount of time designing the perfect cube – the proper dimensionality, formulae, calc scripts, data, and more. Often, the cube serves multiple units or departments and they each have their preferred way of looking at things: hierarchies, views, and more. On the developer/Essbase side of things the functionality is solid and feature-rich. But there may be compromises on the user/interface side of things. This is where Dodeca and the example I’m walking through today really shine. It’s a practical example of how Dodeca can make Essbase better by creating a highly focused and tailored experience for the user. Continue Reading…
PBCS Scripting with Groovy using the PBJ REST API Library
I was talking to a colleague the other day that wants to do some scripting with PBCS using Groovy. Of course, since PBCS has a REST API, we can do scripting with pretty much any modern language. There are even some excellent examples of scripting with PBCS using Groovy out there.
However, since Groovy runs on the JVM (Java Virtual Machine), we can actually leverage any existing Java library that we want to – including the already existing PBJ library that provides a super clean domain specific language for working with PBCS via its REST API. To make things nice and simple, PBJ can even be packaged as an “uber jar” – a self-contained JAR that contains all of its dependency JARs. This can make things a little simpler to manage, especially in cases where PBJ is used in places like ODI.
For this example I’m going to take the PBJ library uber jar, add it to a new Groovy project (in the IntelliJ IDE), then write some code to connect, fetch the list of applications, then iterate over those and print out the list of jobs in each application.
Happy New Year & Best Posts of 2017
My goodness – has another year gone by already? 2017 was busy, to say the least: trips/presentations/booths at Kscope17, Collaborate, and Oracle Openworld, new releases of Dodeca, the Dodeca Essbase Add-in for Excel, Drillbridge, the Outline Extractor, an upgrade to Oracle ACE status, lots of internal development going on, and more.
Speaking of Kscope, did you submit an abstract for Kscope18 yet? The submission deadline is very quickly approaching.
In any case, I covered a lot of ground on the blog this year, and as with last year, I thought it would be fun to take a look at the best and most popular posts of 2017!
Evolution of Essbase: new URL-based drill-through showed up in 11.1.1.3
Continuing on with the idea of getting insight into the Essbase feature set over time, as viewed through the lens of its Essbase Java API evolution, you can quite clearly see that the open/URL-style drill-through (as opposed to classic LRO-based drill-through) showed up in version 11.1.1.3, which in fact is pretty much the only thing that seemed to get added to this particular release, Java API-wise, along with some ancillary drill-through methods/functionality in some related classes.
More near to my heart: this is the exact functionality that paved the way for Drillbridge! Although it wasn’t available as a feature on day 1, subsequent versions of Drillbridge gained the ability to automatically deploy drill-through definitions to a given cube, and it uses exactly these API methods to accomplish it.
Drillbridge as drill-through solution with CSV data and replacing Access
An interesting use-case has come up with Drillbridge recently where drill-through is currently being “handled” with an Access database. I put the quotes around handled because the current solution requires the user to look at the current POV and then go fetch the corresponding data from an Access database. You might be thinking that this setup is horribly sub-optimal, but I wouldn’t characterize it as such. In my career on all sides of Hyperion – a developer, a consultant, and software developer – I have seen this pattern (particularly those involving Access) pop up again and again.
Access is often (perhaps all too often) the glue that binds finance solutions together, particularly in cases like this involving drill-through. It’s cheap, you can use it on the network simply by dropping the file onto a share drive, it gives you a quick and dirty GUI, and more. Many EPM projects I have been on involve many deliverables, often including drill-through. And all too often those projects had to cut it due to budget and time constraints. And if it gets cut, sure, finance might have to do the “quick and dirty” option like this with Access.
Now, the request du jour: use Drillbridge to quickly implement true drill-through, where the data currently resides in an Access database? A couple of options come to mind:
- JDBC to ODBC data bridge to access current Access database
- Export Access data to relational database
- Export to CSV and access via JDBC CSV reader
- Read CSV dynamically using Drillbridge’s embedded database
I won’t bore you with an exhaustive discussion of the pros and cons of these options, but I will say that the JDBC/ODBC bridge was a non-starter from the get-go (for me), mostly because I looked into it for another project years ago and the general consensus from Sun/Oracle was a) don’t do that [anymore] and b) performance is not too great. Regarding exporting Access to a relational database, yes that is more towards the ideal configuration, but if that were an easy/quick option in this case, we probably wouldn’t be on Access already (i.e., for whatever reason, finance didn’t have the time/patience to have the IT department stand up and manage a relational database, to say nothing of maintenance, ETL, and other things). Next, while there are a handful of JDBC CSV readers, they seem to have their quirks and various unsupported features, and hey, as it turns out, Drillbridge’s embedded database actually ships with a pretty capable CSV reading capability that let’s us essentially treat CSV files as tables, so that sounds perfect, and bonus: no additional JDBC drivers to ship. So let’s focus on that option and how to set it up! Continue Reading…
Speed up ASO SQL data loads by using multiple rules files
Just another quick post today about possibly speeding up data loads to an ASO database when loading from SQL. I got on a quick call with a former colleague that was looking to gain a little more performance on their load process to a massive ASO database, and the first thing that jumped out at me was that I recall you can do parallel loads with some native MaxL syntax.
Here’s a quick example of the syntax:
import database $APPLICATION.$DATABASE data connect as $SQL_USER identified by $SQL_PW using multiple rules_file $RULE1, $RULE2, $RULE3, $RULE4, $RULE5 to load_buffer_block starting with buffer_id 100 on error write to "errors.txt";
Basically, you provide multiple rules files (configured for your SQL datasource of course). The rules files are likely to be the same as each other but I suppose it’s possible you might want to partition the data in some logical way to try and speed things up even more.
For example, let’s say that in the code above, we are loading five years of data from a relational database. We might then make it so that each rule is set for this particular year by doing the following things:
- Set the year in the data header
- Remove that column from the list of
SELECTcolumns - Put a filter/predicate in the
WHEREclause on the query - Bonus points for using substitution variables in both the header definition and the where clause
Performance in this particular use case went up substantially. It’s my understanding that data loads that were taking an hour are now cut down to 17 minutes. Your mileage may vary, of course.
Let’s Not Forget About Hybrid BSO
That said, I think this can be an effective strategy for trying to squeeze performance out of some ASO cubes that need a smaller load window and you don’t want to go changing a lot of the internals in play. If you’re doing new development, then I strongly, strongly recommend using hybrid BSO (or rather, BSO and making sure the cube is configured properly so as to get the hybrid BSO performance benefits). I have been seeing hybrid BSO cubes absolutely killing it in performance, what with their ability to leverage ASO technology for aggregates, and massive calculation improvements owing to the smaller block sizes and indexes you get from having so many dynamic calc members in dimensions. Plus, you of course get all of the classic/rich/awesome BSO functionality out of the box, like dynamic time series, expense tagging, time balance, and more. These were never very strong areas for ASO and often required a lot of non-optimal workarounds to make users happy.
New webpage for Essbase Java API evolution
A fair bit of my job is dealing with and building solutions around the Essbase Java API. For many years, the Java API has been the premier way to programmatically work with Essbase (compared to say, the C and VB APIs, which have fallen out of favor). As part of this development work, it’s often important to see when (in terms of version) a certain class, method, interface, or other object has been added, modified, removed, or deprecated.
As a bit of a side project, I have been working with a library for comparing Java JARs to each other (japicmp). By processing and interpreting the results of just about every single Essbase Java JAR from 7.0.1, through the 9.x series, multiple 11.x’s, and finally to version 12.2.x, I have come up with something of a master table that shows all of these changes. You can view the initial results of the Essbase JAPI JAR evolution analysis. I’ll probably refresh this and enhance the output as new library versions become available or as I determine that additional insights become useful.
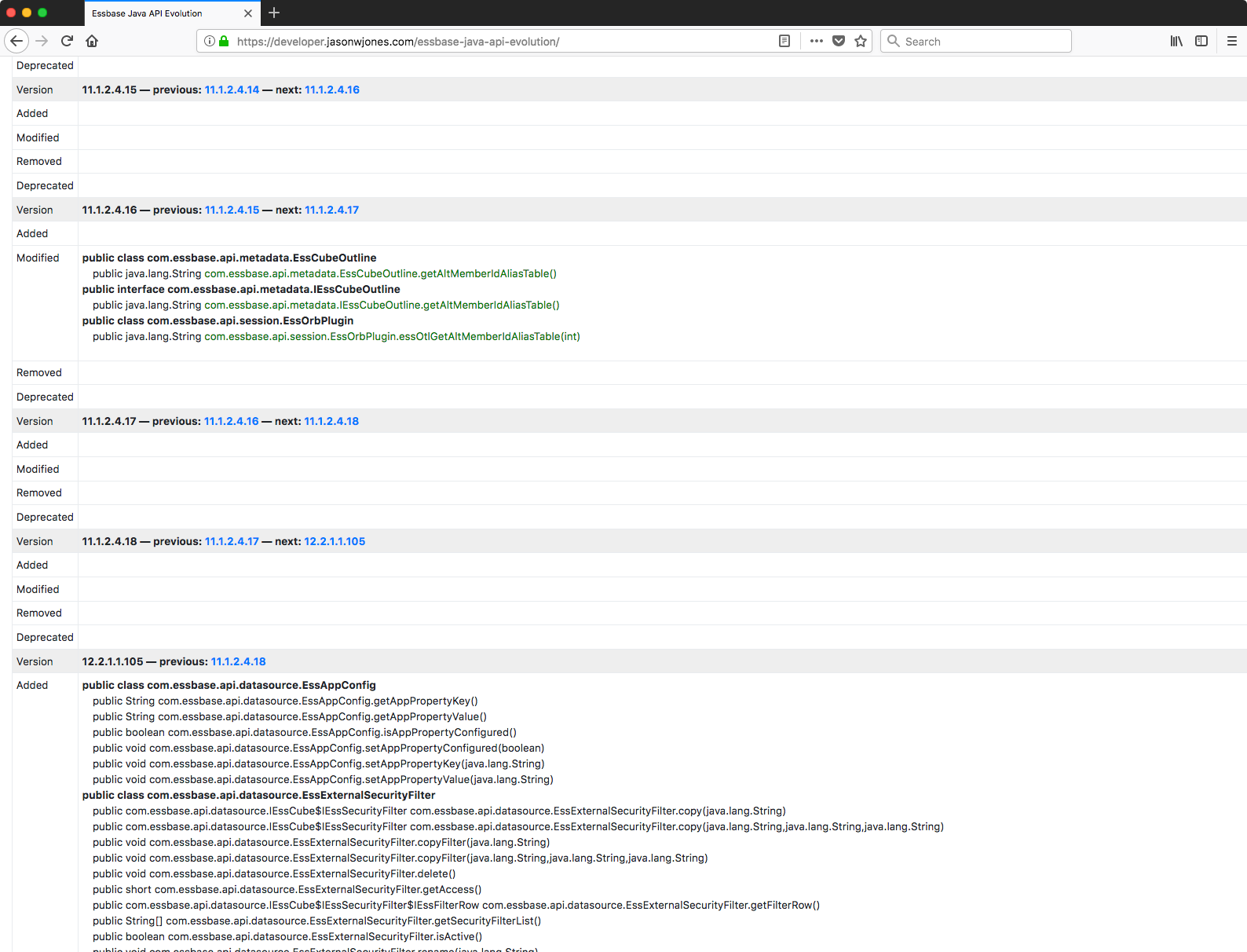
Screenshot from the Essbase Java API evolution analyzer
Configuring Drillbridge with Financial Reporting Web Studio
Drillbridge works perfectly with Financial Reporting Web Studio – the successor to the desktop-based version of Financial Reporting (also commonly called HFR, FR). FR was stuck with a very archaic client (let’s just say it’s from around the Clinton administration), but it has revamped for the future, with a completely web-based interface now. In retrospect, and based on my interactions with the interface, I think this product overall can be thought of as gap coverage for FR users. It’s not necessarily the place you want to do new development, especially given some of the other shifts/developments in the reporting ecosystem lately. My colleague Opal Alapat has posted some really great thoughts on FR and its place in this ever-changing world, which I encourage you to read.
In the meantime, there are countless current installs of FR that organizations need to support and perhaps transition to this newer incarnation of FR. As with before, Drillbridge works seamlessly to give you and your users advanced drill-through capabilities in Smart View, Hyperion Planning/PBCS, FR, and now FR web. I found that the UI had a few quirks to it, but I’ll walk through a simple example and try to point those out along the way.