I started writing this recap at the airport in San Jose, waiting for my flight back to Seattle, but the article got a bit longer than I thought so I’m just not finishing it up here on Monday. As expected, the conference itself was great, the food was even better, and it was fun meeting all the people. One of the things that the ODTUG organizers pointed out was this is one of the very few conferences that has grown in attendance this year. It’s very easy to believe that due to economic conditions, companies are cutting back on travel dollars — and I think it’s a testament to the quality of content [and food] of ODTUG that even with these conditions, the attendance has grown.
I flew in Saturday evening. Due to scheduling issues, I wasn’t able to get in earlier and help pull “evil ice plant” (an invasive plant species) from one of the local nature areas, but it’s my understanding that the other ODTUG attendees pulled an absolutely ginormous amount of the stuff, so kudos to my colleagues for that.
The conference-proper started on Sunday morning and as expected there were lots of important people talking about roadmaps and future plans and synergy and all of that fun stuff. That’s all well and good, but it can be a little difficult for me to get jazzed up about such things because they are still months away from being released, and on top of that, it would be even longer until I could get a hold of it, understand it, and put it to use, not to mention the fact that new releases of software (particularly in the Hyperion world) tend to be a little rough around the edges (to be charitable). The general consensus, though, seems to be that Oracle is dumping a lot more money on R&D, development, and polishing things up, so one is hopeful that new releases earn a better reputation than their predecessors.
One of the more entertaining aspects of Sunday was Toufic Wakim giving a presentation on the state of Smart View, which was not only funny because of Toufic’s energetic and humorous delivery style, but also because during the presentation, the audience was quite vocal about the shortcomings of the product and why they can’t roll it out to their users. As has happened before, much love was expressed for the power and simplicity of the classic Excel add-in. Toufic seemed very interested in collecting and recording people’s feedback so that future releases of Smart View will be better.
It was hard to go more than a few minutes during the conference without hearing about Twitter and tweets and everything else along those lines. Twitter was extensively embraced. I’m not really much of a Twitter guy so I didn’t really follow the conference in that way. It did, however, seem like the usage and mentioning of Twitter died down significantly as the conference went on, which I can’t really say was a bad thing. If nothing else, it allowed for more bandwidth to the conference and hotel rooms, which was grossly inadequate, to say the least (with thousands of geeks pounding the network, transfer speeds were dismal). Apparently the checklist for next year’s ODTUG involves verifying that the hotel can accommodate all of the net traffic that is sure to occur at such a conference.
Among the conferences I attended on Monday was Ed Roske doing one of his calc script presentations, Matt Millella’s Top 5 Essbase CDFs, and “Building Sustainability Dashboards with Oracle EPM.” All were interesting and the CDF presentation really hit home since I’ve been using CDFs lately, and have a toolchain setup to roll new functionality into Jar files and deploy it.
Monday was also the day that I gave my presentation on Dodeca during the vendor slot. Tim Tow and I had a good sized audience while I showed how Dodeca has been a good fit for my company. It was the first presentation I’ve given (ever), so although I’d say it generally went okay, now that I have a couple presentations under my belt I am feeling more comfortable and thinking of ways to improve them. I suspect that as with most things, the more you do it the better you get. So for anyone out there that hasn’t given a presentation and has been thinking about it but couldn’t quite pull the trigger, I whole heartedly encourage you to throw your name in the hat and give it a shot.
On Tuesday I checked out Ruddy Zucca and Steve Liebermensch talking about ASO. I had seen Steve’s presentation on ASO last year as well. I had gone home from ODTUG New Orleans with a list of things to try out to make some of my ASO cubes a little snappier, and I am happy to say that I am going home from this ODTUG as well with a few more ideas on how to squeeze a little more performance out of my ASO cubes — and improve the Essbase reporting experience for my users.
As an aside, the week of the conference was “closing week” at work, meaning that the fiscal period is over and mountains of data need to be loaded up to various databases. Normally taking time off during closing week is almost impossible, but the automation systems are pretty dialed in so we thought it’d be okay. Although things largely went off without a hitch, there were a couple of small issues so I had to skip a few sessions to VPN to work and check in on things. In most cases, re-running a job seemed to fix things up. So I’m very happy to say that I have just about automated myself out of a job. Oh wait…
On Wednesday I checked out Glenn Schwartzberg talking about “Little Used Features in Essbase,” which was pretty interesting. He talked about Triggers and all sorts of miscellaneous things that don’t quite warrant their own session but combined together made for an interesting presentation. He didn’t quite get to Data Mining, which could warrant a session all on it’s own. Oddly enough, it’s now my understanding that the data mining features of Essbase were supposed to be removed from the latest release (presumably because this functionality will be provided elsewhere in the Oracle stack). It came as a surprise to at least one Oracle employee that the functionality in question was still around. (Oops!)
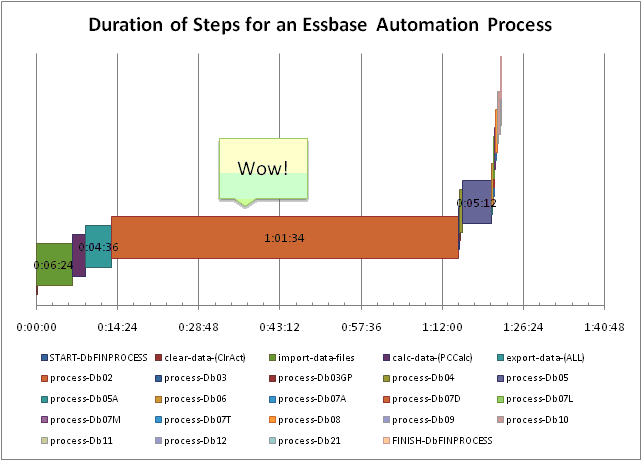
Later in the day I presented on Optimizing Loads and Builds with Kevin Corlett. Kevin was an awesome co-presenter and had a ton of great content to add to the presentation. As with my Dodeca presentation, I felt pretty good about the content and I’m confident that if I presented again I could make it even better. The original abstract I wanted to present on was about not just loads and builds but about taking an entire automation process and squeezing every last drop of performance out of it. I currently have a job that takes about an hour and a half to run and one of my projects this summer is to rebuild it to get the processing time down a bit. I am fairly confident that I can get this below 5 minutes. So with any luck, next year I’ll be able to present on this.
After my presentation I checked out Rohit Amaranth’s presentation about Essbase in the Clouds. This was a very interesting topic. The idea is that instead of buying or leasing your own hardware, you put Essbase in the cloud. “In the cloud” is a bit of a buzzword right now, so Rohit took a moment to explain what it was and what it wasn’t. My big takeaway is that the cloud computing model treats computational resources as elastic and a platform to build on, and this can significantly alter the economics of utilzing computing capacity. Instead of having to go through the process of acquiring or leasing hardware that you are “stuck” with, why not rent out the service and pay for what you use. Although there are still some licensing issues to sort out with Oracle, I am extremely interesting in seeing how this model could be used to setup test servers.
The next thing I did on Wednesday was sit on the Optimization Roundtable with Ed Roske, Steve Liebermensch, and Cameron Lackpour. Glenn Schwartzberg was the moderator and went around the room letting people ask their optimization questions. The content of the questions tended to focus largely on hardware issues. Although I find hardware interesting and necessary to provide a service to my users, I don’t spend a lot of time dwelling on it since for the most part ‘It Just Works’ and performance issues [for me] tend to be dealt with on the software side. So, sadly, I didn’t have much of a chance to show off much Essbase knowledge, although Steve wound up fielding a bunch of ASO questions and providing some insight on things as a current Oracle employee.
Finally, Thursday was a light day filled with “Best of” sessions from earlier in the week. There was a bit of a mixup for the first session so a bunch of us that had gathered for that wound up having a bit of an adhoc session discussing various Essbase topics. In a lot of ways this was actually one of the more fun sessions. After that I went to Cameron’s session on mastering Essbase with MaxL automation. Although he didn’t think I’d pick much out of it, I actually did. For example, I now know what MaxL stands for (probably) and saw a couple of neat things on encrypting MaxL files. Plus, as an added bonus, I got to heckle him during his presentation, and that alone made it worth it.
Last, but certainly not least, I went to Angela Wilcox’s session on automation with Perl scripting. This topic is interesting to me for a number of reasons, one, I used to be quite the Perl programmer back in the day (although sadly I can barely do a Hello World program anymore), and two, getting up an running with Perl for Essbase can be a formidable challenge — especially due to the scant documentation provided by Hyperion/Oracle. The presentation was quite interesting and it looks like her group has done some nice things to simplify their automation. I am definitely going to take a look at where I could simplify some of my systems with some Perl scripts.
So, that was the conference in a nutshell for me. For all of you that couldn’t attend, it’s my understanding that the ODTUG website will have the slides up within 90 days so you’ll be able to check out the content then. If you’d like my slides from the Data Load Optimization presentation, just shoot me an email and I’d be happy to send them your way.