This issue has been on my radar for awhile and I finally had a chance to dig into it the other day. I noticed an occasional issue for an ODI job that journalized a large source table and updated corresponding rows in a target on another system. The source and target are both Oracle databases so I’m using the DBLINK LKM and in this case using the MERGE IKM.
If you’re not familiar with journalized tables in ODI, it’s a really great feature that allows you to track rows that are inserted/updated on a table and then process only those rows when you run the interface. This capability is leveraged simply by way of a checkbox to tell the interface to only process the new rows (of course, setting up the journalization itself is a couple of extra steps but it’s also pretty straightforward). Journalization is incredibly useful in a variety of situations. The main one is that if the source is huge, you can’t or don’t want to process the entire table just to sync up with a target.
In addition to being able to track inserted and updated rows, with a simple option you can also synchronize deletions. This means that if a row gets deleted in the source, you have the option to delete the corresponding row (based on the primary key) in the target. I’d say about half of the interfaces I make with journalization have this option turned on and half have it turned off.
That all being said, I have a few interfaces at a client that have synchronize deletions turned on, but the sources very rarely get a row deleted. In fact, they almost never get a row deleted. But these interfaces have been failing now and then and the root cause turns out to be that some rows in the source were being manually deleted. The actual error as seen in ODI, however, is that an insert to the target table is failing on account of the ODI job trying to insert null values into columns that require non-null values. Curiously, these rows were not null in the source. As it turns out, ODI was getting null values because it was doing a left outer join with deleted records (generating records with just a primary key and all null fields).
But wait, shouldn’t these be deleted? Yes! I dug through the steps in the Operator, however, and there was no step that was deleting these rows from the flow table. So let’s take a look at the steps in the IKM:
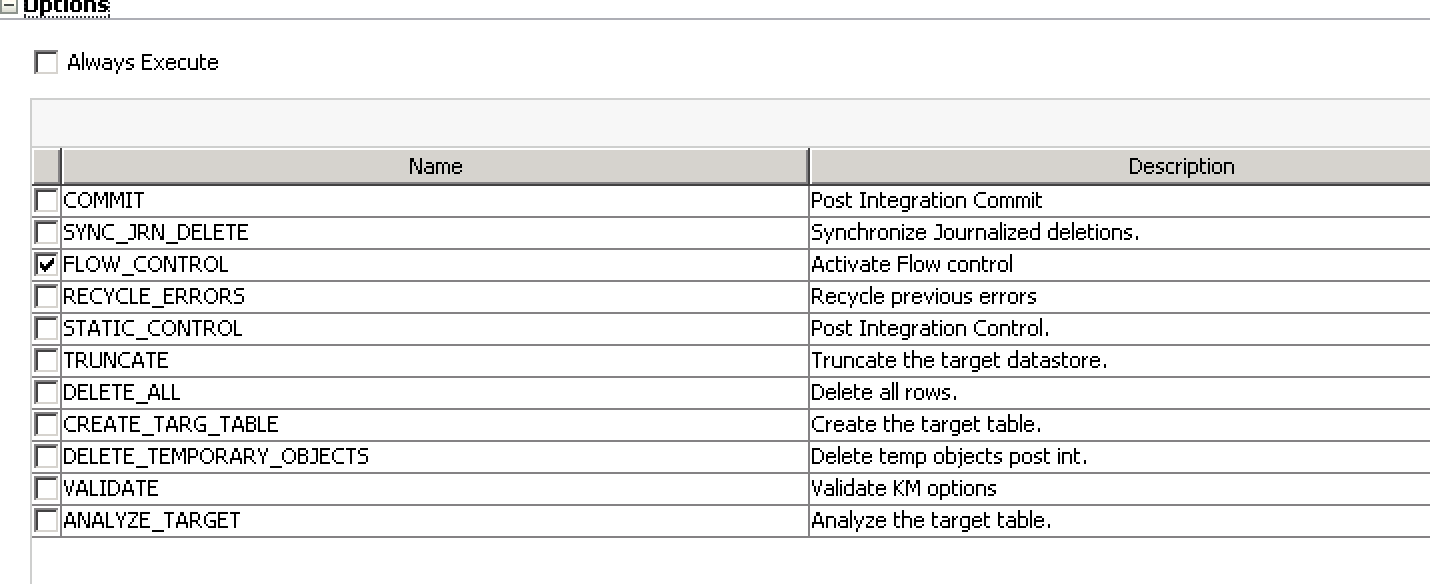
I see two critical steps with Order 140 and 150. Step 140 “Synchronize deletions from journal” is running and does exactly what we think it should do: delete records from the target that were deleted in the source. So far so good.
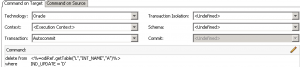
But based on analysis, this left some rows in the flow table (the temporary ODI staging table) that were just getting reinserted once again. But there’s a step for handling that!
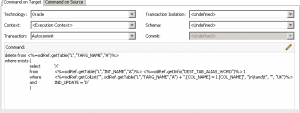
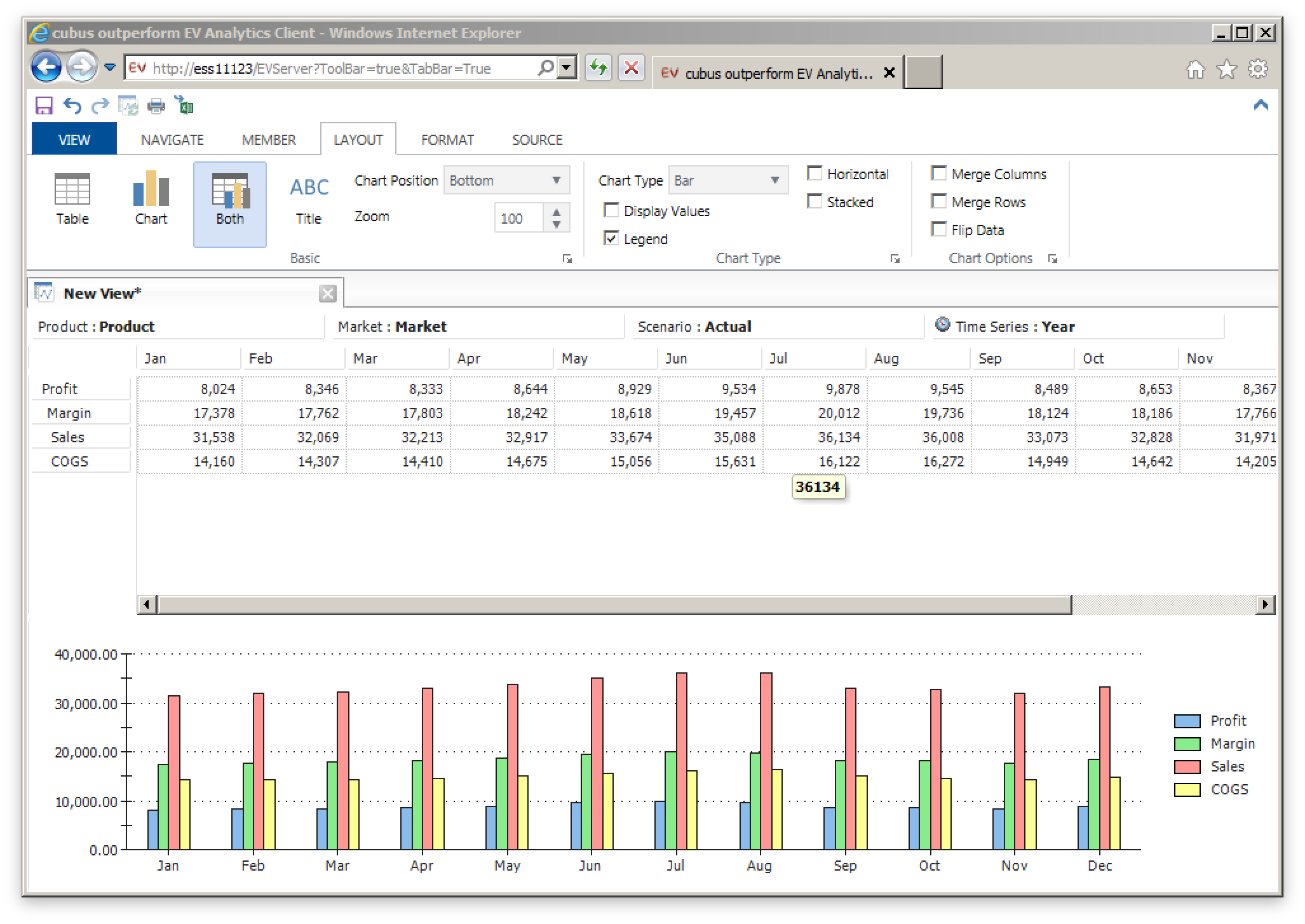
We have the “remove deleted rows from flow table” that removes the deleted rows from the flow table, so that they therefore won’t be part of the join that creates the rows to go to the target. But why isn’t that step running? Well, it’s set to only execute if the FLOW_CONTROL option is set, as shown below:
So, perhaps counterintuitively (for me, right now, at least…) the synchronize deletions is dependent on FLOW_CONTROL being turned on, and the issue was that Flow Control was turned off in this job. I don’t think this is a bug, but if caught me by surprised. I turned the option back on (the default is actually on but it was off for whatever reason), regenerated the scenario, and this issue is solved for now. At the moment I am of the thinking that this step shouldn’t be tied to Flow Control but I’m not going to question it for now. Hopefully this helps someone out down the road (but more likely I’ll Google it in a couple of years and help myself out, which curiously was the original motivation for this blog…)